您现在的位置是:抑強扶弱網 > 鐵嶺市
檸檬工坊怎麽樣(加盟檸檬工坊怎麽樣)
抑強扶弱網2025-07-05 07:55:46【鐵嶺市】4人已围观
简介前幾天谘詢了源動力餐飲的檸檬工坊項目?不知道有沒有加盟感覺如何啊?很好,屬於原動力集團,他們是做食物加盟的,很好的公司。我想加盟一個奶茶店,哪個品牌比較好。。。求各位推薦!用產品和地址留住顧客的方式太
前幾天谘詢了源動力餐飲的檸檬工坊項目?不知道有沒有加盟感覺如何啊?
")
很好,屬於原動力集團,他們是做食物加盟的,很好的公司。
我想加盟一個奶茶店,哪個品牌比較好。。。 求各位推薦!
用產品和地址留住顧客的方式太有限,這種時候需要非常成熟的營銷係統,能夠積極吸引顧客。(威廉莎士比亞,溫斯頓,商品名言)。對於沒有太多開店經驗的人來說,這幾乎是不可能的。加盟的品牌方必須具備其實力,提供全方位的營銷支持。
本文到此結束,希望對大家有所幫助呢。
很赞哦!(416)
上一篇:
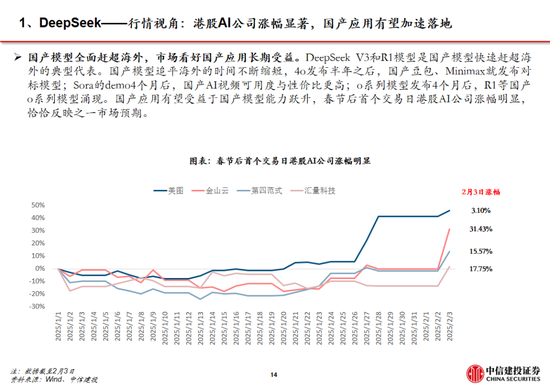
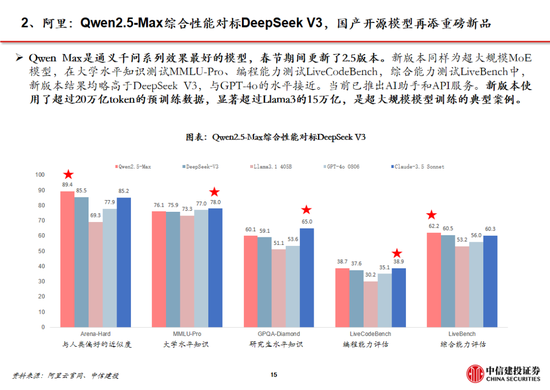
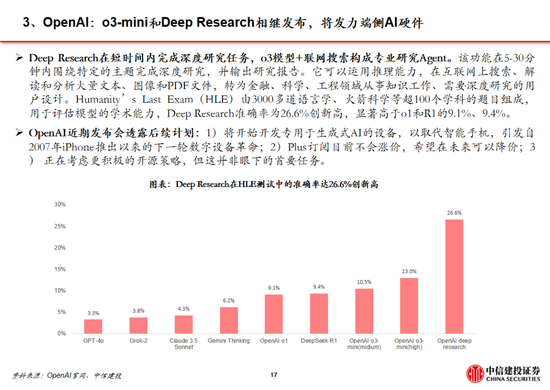
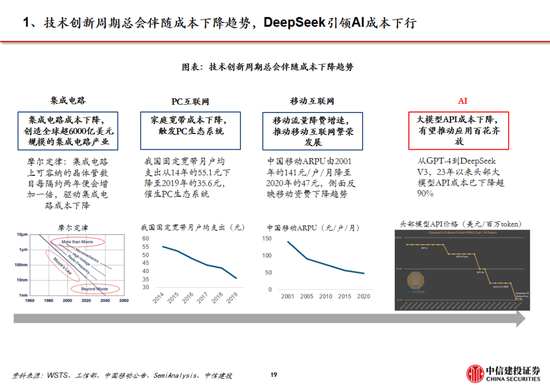
中國銀行:2月10日起調整積存金產品的購買條件 上調積存金起購點至700元DeepSeek到底橫掃了什麽?比“爭創新”更重要的,是“講邏輯”馬斯克的改革會讓美國更偉大還是衰落?DeepSeek這樣回答02195510是什麽電話(+262是什麽電話)讓農行員工不下班也要等的人,究竟是……7月27日什麽星座(2013年10月27日是什麽星座)壓力是什麽意思(公稱壓力是什麽意思)機構:2024年全球平板電腦出貨1.476億台,小米躍居第五標簽是什麽意思(微信標簽是什麽意思)什麽屬相不能住西戶(什麽屬相不能住18樓)劉嘉玲什麽星座(劉嘉玲上升什麽星座)以軍已完全撤出內察裏姆走廊1%紅線劃定!險資黃金投資試點啟航重磅!特朗普簽令:暫緩征稅!白宮恢複中國小額包裹免稅待遇寒武紀主題曲叫什麽(寒武紀的小說叫什麽)metoo是什麽意思(youtoo是什麽意思英語)OpenAI奧爾特曼稱要打造歐洲版“星際之門”,首個圈地選定德國券商是做什麽的(券商中台是做什麽的)拉屎為什麽是綠色的(拉屎為什麽是白色的)JT&N觀點 | 2024年中國保險並購市場回顧變幻的近義詞是什麽(變幻的近義詞是什麽變換)原耽什麽意思(喜歡原耽什麽意思)美兩名滯留太空宇航員或3月19日左右返回宏大民爆集團2025年春季校招儀字五行屬什麽(怡字五行屬什麽)中信建投:DeepSeek產業鏈投資機遇 來源:證券研究 中國DeepSeek爆火全球,為AI行業的發展注入了嶄新的活力,全麵引領AI浪潮。 近期DeepSeek多款模型上線並完全開源,其中R1在推理任務上基本實現於o1相當的性能,Janus-Pro 在多模態理解和生成方麵表現較好。受春節信息傳播下沉促進,DeepSeek出圈並成為全球增速最快的 AI 原生應用,日活躍用戶數在2月1日突破3000萬大關。此外,DeepSeek通過算法迭代、架構升級,使通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下。 中信建投證券計算機、人工智能、通信、傳媒、策略研究團隊推出【DeepSeek產業鏈投資機遇】: 01 DeepSeek核心十問十答 DeepSeek-R1模型發布,具有高性能、低算力需求的特性,帶動小模型推理能力的提升,引發全球開發者及用戶關注。R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權,同時純強化學習對推理能力的提升帶來RL範式泛化可能,預計後續基模的持續迭代,有望推動AI全產業鏈持續保持高景氣和高關注度,關注算力、應用、端側、數據等核心投資機會。 DeepSeek模型密集更新,高性能+低成本促進用戶數高增 近期DeepSeek多款模型上線並完全開源,其中R1在推理任務上基本實現於o1相當的性能,Janus-Pro 在多模態理解和生成方麵表現較好。受春節信息傳播下沉促進,DeepSeek出圈並成為全球增速最快的 AI 原生應用,第18天達到1500萬日活。此外,DeepSeek通過算法迭代、架構升級,使通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下。 技術不斷革新,大模型Scaling Law仍有效 DeepSeek通過多頭潛在注意力、MoE、多token預測等架構和基礎設施創新實現了高效訓練,並在R1-Zero模型驗證了純強化學習對推理能力的提升。盡管Pre-Training Scaling麵臨技術、算力、數據的製約,但強化學習帶來了規模化擴張新方向,預計各廠商將陸續跟進,持續優化模型架構。 DeepSeek-R1促進AI平權,產業鏈享受發展紅利 R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權。同時,R1使小模型具備推理能力成為可能,更低的成本將更有利於開發者探索AI的實際落地。 一、DeepSeek模型密集更新,高性能+低成本促進用戶數高增 1.1 第一問:DeepSeek的用戶量趨勢? DeepSeek堅定開源路線,密集更新MoE、推理、多模態模型。近期,DeepSeek連續發布並開源多個大模型,其低成本、高性能的特性迅速引發全球用戶的關注。其中,2024年12月26日發布的DeepSeek-V3為671B參數的自研 MoE 模型,運行時僅需激活37B,在 14.8T token 的數據上進行了預訓練;2025年1月20日發布的DeepSeek-R1為660B的高性能推理模型,對用戶開放思維鏈輸出,允許用戶通過蒸餾技術借助 R1 訓練其他模型;2025年1月27日,DeepSeek在Hugging Face平台上傳了視覺模型 Janus-Pro和多模態理解模型JanusFlow -1.3B,進一步在圖像領域發力。 DeepSeek Web端與APP端訪問量持續增長,春節信息傳播下沉加速產品關注度裂變。Web端,2024年10月至2024年12月DeepSeek訪問量分別為245/422/1101萬,其中11月和12月分別同比增長72.24%/160.90%,12月受全模型V3促進訪問量大幅增長;APP端,DeepSeek 2025年1月10日(官方公眾號1月15日正式發文)在iOS/Android上線官方APP,而後受益於1月20日發布R1模型的高性能、低成本,疊加春節期間信息傳播下沉,產品關注度呈裂變式增長。具體而言,DeepSeek APP安卓/iOS端國區單日下載量均於1月26日前後迎來陡增,至1月29日單日下載量分別達到784.15/29.92萬;同時,DeepSeek 安卓端在華為應用商店下載排行中位列第四,iOS端則霸榜全球173個地區中160/162/171個總榜(免費)/應用(免費)/效率(免費)第一;此外,從產品發布日起日活用戶看,DeepSeek第5天超過 ChatGPT,第15天以259萬日活達到 ChatGPT 的2倍,亦為全球增速最快的 AI 原生應用,第18天達到1500萬日活,而ChatGPT上線第244天才達到1500萬DAU。 我們認為,DeepSeek用戶數將持續高速增長。一方麵DeepSeek作為開源路線的堅定踐行者,有望受到全球開發者的高度關注;另一方麵受益於春節期間信息傳播下沉,DeepSeek的國內滲透率將持續提升。 1.2 第二問:R1和Janus-pro模型的性能如何? DeepSeek-R1 在推理任務上基本實現與 OpenAI-o1相當的性能,較o3模型仍有差距。DeepSeek在R1模型的測試過程中,選取英文、中文、數學、代碼等基準測試,與Claude-3.5、GPT-4o、DeepSeek-V3、OpenAI o1、OpenAI o1-mini等模型進行比較: 教育為導向的知識任務:在以MMLU(R1 90.8分;V3 88.5分;o1 91.8分)和GPQA Diamond(R1 71.5分;V3 59.1分;o1 75.7分;o3 87.7分)為代表的知識基準上,R1相比V3表現出更優越的性能,主因大規模強化學習(RL)促進STEM相關問題上準確性顯著進步;在依賴長上下文的FRAMES(R1 82.5分;V3 73.7分)基準,R1同樣展示了強大的文檔分析能力。 中英文搜索和數據分析任務:在英文事實基準測試SimpleQA(R1 30.1分;V3 24.9分;o1 47.0分)上,R1優於V3,展現了模型基於事實的查詢能力;而在中文事實基準測試C-SimpleQA(R1 63.7分;V3 68.0分)上,R1表現不如V3,主要係安全強化學習後模型傾向於拒絕回答某些查詢。如果沒有安全RL, R1的準確率可以超過70%。此外,R1模型在IF-Eval(R1 83.3分;V3 86.1分)、AlpacaEval2.0(R1 87.6分;V3 70.0分)和ArenaHard(R1 92.3分;V3 85.5分)等基準測試中同樣表現較好,展現了模型在遵循格式指令、寫作任務和開放域問答上的能力。 數學任務:在數學任務上, R1 表現出與 o1相當的性能,優於其他非推理模型,突出了推理模型在數學測試中的主導地位。例如在AIME 2024基準上,R1/V3/o1/o3分別得分79.8/39.2/79.2/96.7分;在Math-500基準上,R1/V3/o1分別得分97.3/90.2/96.4分。 編碼任務:推理模型在數學測試中同樣表現更佳,例如在Codeforces基準上,R1/V3/o1/o3分別得分2029/1134/2061/2727分,分別超過96.3%/58.7%/96.6%/99.9%的人類參賽者;在SWE-bench Verified基準上,R1/V3/o1/o3分別得分49.2/42.0/48.9/71.7分。 蒸餾技術能顯著提升小模型推理能力。通過向更高效的小模型蒸餾DeepSeek-R1的輸出,能夠顯著提升小模型推理能力。例如,向Qwen2.5-Math-7B蒸餾R1模型得到的DeepSeek-R1-Distill-Qwen-7B(簡稱R1-7B,下同),全麵超越非推理模型如GPT-4o;向Qwen2.5-14B蒸餾得到R1-14B在所有評估指標上均超過了QwQ-32B-Preview;而向Qwen2.5-32B和Llama-3.3-70B-Instruct蒸餾得到的R1-32B和R1-70B在大多數基準測試中顯著超越了o1-mini。 Janus-Pro 在多模態理解和生成方麵優於統一模型和單一功能模型。Janus-pro主要延續Janus通過解耦多模態理解和生成的研究思路,通過優化訓練策略、擴展訓練數據和模型規模等方麵提高模型性能: 多模態理解:在Janus測試過程中選取POPE、MME-P、MMB、SEED、MMMU、MM-Vet等廣泛認可的圖像視覺語言基準測試,同時包括了一種用於真實世界視覺推理和組合式問答的新數據集GQA。與其他前沿圖像理解生成統一模型和僅用於理解的模型相比,Janus-Pro 取得了總體最佳的結果,例如Janus-Pro-7B在多模態理解基準MMBench上得分79.2,超越了包括Janus(69.4)、TokenFlow(68.9)和MetaMorph(75.2)等,主因其將多模態理解和生成的視覺編碼解耦,緩解了這兩個任務之間的衝突。此外,Janus-Pro與規模更大的模型相比仍具競爭力,例如Janus-Pro-7B在除GQA外的其他基準測試上的表現都優於 TokenFlow-XL(13B)。 文本-圖像生成:為評估Janus視覺生成能力,DeepSeek采用 GenEval(文本到圖像構圖能力基準測試)和 DPG-Bench(密集提示圖基準測試)兩個工具進行測試。Janus-Pro-7B 在 GenEval 上的總體準確率達到 80%,超過了所有其他統一模型或僅用於生成的模型,包括Transfusion(63%)、SD3-Medium(74%)和 DALL-E 3(67%),反映Janus-Pro具有更好的指令跟隨能力。同時,Janus-Pro 在 DPG-Bench 上的得分為 84.19,超過了所有其他方法,表明 Janus-Pro 在遵循用於文本到圖像生成的密集指令方麵表現出色。 我們認為,DeepSeek-R1性能已基本達到OpenAI-o1水平,較o3模型基準測試表現仍有不小差距,隨著DeepSeek在MoE架構、強化學習等技術上進一步迭代,推理模型性能表現有望持續增長;Janus-Pro在多模態理解和生成方麵則相對表現較好,一定程度驗證了圖像理解和生成解耦思路的可行性。 1.3 第三問:如何看待DeepSeek-V3模型的訓練成本? DeepSeek通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下: 通用模型方麵,2024年12月26日DeepSeek-V3更新上線,模型API服務定價調整為每百萬輸入tokens 0.5元(緩存命中)/ 2元(緩存未命中),每百萬輸出tokens 8元。此外,V3模型設置長達45天的優惠價格體驗期:2025年2月8日前,V3的API服務價格仍保持每百萬輸入tokens 0.1元(緩存命中)/ 1元(緩存未命中),每百萬輸出tokens 2元。與此同時,OpenAI GPT-4o的API服務定價為每百萬輸入tokens 1.25美元(緩存命中)/ 2.5美元(緩存未命中),每百萬輸出tokens 10美元。 推理模型方麵,DeepSeek-R1 API 服務定價為每百萬輸入 tokens 1元(緩存命中)/ 4元(緩存未命中),每百萬輸出 tokens 16元。而OpenAI o1的API 服務定價為每百萬輸入 tokens 7.5美元(緩存命中)/ 15美元(緩存未命中),每百萬輸出 tokens 60美元。 需要注意的是,不同模型token切分方法可能不同,通常1 token可對應1-2個中文漢字,或對應3-4個英文字符,或0.75個英文單詞。 DeepSeek-V3(R1的基礎模型)總訓練成本僅為 557.6 萬美元,但不包括架構、算法等成本。以H800算力計算,DeepSeek-V3預訓練階段在不到兩個月的時間內完成,耗費266.4萬個GPU小時,加上上下文長度擴展所需的11.9萬個GPU小時和後訓練階段的0.5萬個GPU小時,DeepSeek-V3的完整訓練僅需 278.8 萬個 GPU 小時;假設 H800 GPU 的租用價格為每 GPU 小時 2 美元,我們的總訓練成本僅為 557.6 萬美元。需要注意的是,上述成本僅包括 DeepSeek-V3 的正式訓練成本,不包括與架構、算法或數據的前期研究及消融實驗相關的成本。 根據我們測算,GPT-4需要2.5萬張A100訓練95天(5700萬A100 GPU小時),OpenAI o1需要用3.2萬張H100訓練90天(6912萬H100 SXM GPU小時):1)GPT-4由16個111B的MoE模型構成,其中兩個用於向前傳播,另有55B被用做注意力機製的共享,則GPT-4的激活參數量約為280B,我們假定o1模型激活參數量是GPT-4的兩倍,達到560B;2)GPT-4的預訓練數據集token量為13B,我們假定o1模型接近其兩倍,達到25B;3)GPT-4的訓練時間約為90-100天,我們取中間值95天,並假定o1的訓練周期為90天;4)GPT-4的GPU利用率在32%到36%之間,我們取中間值34%,並假定o1 GPU利用率也為34%;5)根據OpenAI在Scaling Laws 論文中給出的經驗公式計算(C = rT ≈ 6*P*D,P為模型參數量,D為訓練集token大小,r為訓練集群硬件FLOPS總吞吐),則OpenAI o1預訓練需要用3.2萬張H100。 算法迭代、架構升級促進DeepSeek-V3模型訓練成本降低,符合產業趨勢。相較於GPT-4和o1模型,DeepSeek-R1的基礎模型DeepSeek-V3訓練成本明顯更低,結合V3技術報告和上述計算過程,我們認為成本優化主要緣於:1)V3模型通過DeepSeekMoE架構(3.1中將進一步說明),使用更細粒度專家模型,同時隔離部分共享專家,提高計算資源利用率,激活參數少(僅37B),算力消耗低;2)V3模型采用MLA算法(3.1中將進一步說明),通過低秩聯合壓縮注意力鍵值,減少推理時的鍵值(KV)緩存,降低計算量;3)Dual Pipe框架實現高效流水線並行,或顯著提高GPU利用率;4)DeepSeek提出了一種利用FP8數據格式進行訓練的細粒度混合精度框架,通過低精度訓練優化訓練效率。 二、技術不斷革新,大模型Scaling Law仍有效 2.1 第四問:DeepSeek-V3/R1技術革新有哪些? 通過架構和基礎設施創新,DeepSeek-V3實現了高效訓練,奠定R1模型優化基礎。架構方麵,DeepSeek-V3延續了V2模型的MLA和DeepSeek MoE架構,同時進一步開創了無輔助損失的負載均衡策略,並設定了多token預測(MTP)訓練目標以增強性能: 多頭潛在注意力(MLA):LLM的核心機製是自注意力(Self-Attention),其要求模型在生成每個token時考慮之前所有詞的關係,則假設文本長度n時總體複雜度為〖O(n〗^3)=O(Σn^2);過去的研究提出了KV Cache方法,利用鍵值對(KV)存儲已計算的注意力信息,此時總體複雜度降低為O(n^2);而MLA則進一步通過投影的方式,將token的相異信息通過投影矩陣存儲,在幾乎不損失信息的情況下減少鍵值的緩存需求。 DeepSeekMoE:專家混合模型(MoE)是當前大模型技術中對前饋神經網絡(FNN)的一種替代方案。不同於FNN需要全部權重參與計算,MoE利用門控機製判斷輸入數據需要由哪些專家模型參與處理。相較於主流MoE模型,DeepSeekMoE使用更細粒度的專家,並隔離一些模型作為共享專家,進一步優化了激活參數。此外,為解決專家負載不平衡導致的路由崩潰和計算效率降低,DeepSeek提出無輔助損失負載均衡策略,為每個專家模型添加可動態調整的偏差項,確保訓練過程中專家負載平衡、提高模型性能。 多token預測(MTP):主流大模型token-by-token生成序列,而每次token生成需要頻繁與訪存交互,從而因為訪存效率形成訓練或推理的瓶頸。MTP方法主要將單token的生成,轉變成多token的生成,提升訓練和推理的性能。DeepSeek主要對過往MTP算法進行了一定優化,順序預測額外token,並在每個預測深度保持完整的因果鏈。 除了基礎架構,DeepSeek還在基礎設施方麵進行了一定優化。例如設計了一種創新的管道並行算法 DualPipe,在每一對前向和後向塊內重疊計算和通信,提高通信效率、加速了模型訓練;提出了一種用於 FP8 訓練的混合精度框架,其中大多數計算密集型操作在 FP8 精度下進行,而一些關鍵操作則戰略性地保持在原始數據格式以平衡訓練效率和數值穩定性;訓練過程中,采用英偉達 PTX(並行線程執行)匯編級編程替代標準 CUDA 方案,實現了硬件級深度優化,減少了計算冗餘,提高了推理速度。 R1-Zero驗證純強化學習(RL)對推理能力的提升,R1則強調冷啟動和多階段訓練的平衡。R1-Zero的特別之處在於,其無需任何監督微調數據即可獲得強大的推理能力,反映了模型僅通過強化學習就能有效學習和泛化的能力。具體而言,R1-Zero模型在RL過程中延續了DeepSeek-V3組相對策略優化算法(GRPO),通過組內獎勵對比優化策略,而不需要額外的判別器,最終實現訓練集上的平均響應長度持續提升,自然地學會了通過更多的思考時間來解決推理任務;此外,R1-Zero訓練過程自然地湧現出“思考能力”,即模型自發學會了重新評估其初始回答,並為問題分配更多的思考時間,這種“反思”的特性能夠一定程度解決大模型幻覺問題(大模型逐token輸出,過去沒有機製去糾正已經輸出的錯誤,反而會繼續用錯誤掩蓋先前的問題,帶來幻覺問題)。 盡管R1-Zero模型展現了強大的推理能力,但仍麵臨可讀性差和語言混合等挑戰,R1模型則通過冷啟動和多階段訓練解決了上述問題。R1同樣從DeepSeek-V3-Base基礎模型出發,經過數千條優質長鏈思維(CoT)數據微調(SFT)作為冷啟動,使模型輸出更符合要求、可讀性更強;而後,針對微調後的模型采用與R1-Zero相同的大規模強化學習,並引入語言一致性獎勵,直至模型在推理任務上達到收斂;麵向推理的強化學習收斂後,利用生成的檢查點收集新的SFT數據,從而融入來自其他領域的數據,以增強模型在寫作、角色扮演和其他通用任務中的能力;最後,為了進一步使模型與人類偏好保持一致,實施次級RL階段,旨在提高模型的有用性和無害性、精煉其推理能力。通過冷啟動和多階段訓練,R1模型最終具備較強的推理性能,同時在可讀性上表現較好。 R1係列模型提供了RL Scaling Law的可行方向。實際上,在OpenAI推出o1模型時即發現了推理性能隨著訓練時間和測試時間計算而平穩提升的“RL Scaling law”,但業內尚未通過過程獎勵模型(PRM)和蒙特卡洛樹搜索(MCTS)等方法做出較好的效果,R1的技術報告更是提到PRM和MCTS存在難以規模化拓展、獎勵欺騙等問題。R1模型的技術報告提供了一種多階段訓練的方式,其中在第一階段RL過程中,研究人員可以通過擴大RL訓練集的方式提升模型性能,或為一種可以驗證的“RL Scaling law”方向;OpenAI首席研究官Mark Chen也承認,“DeepSeek的確獨立發現了一些o1的核心思路”。 蒸餾使小模型具備較強邏輯推理能力的思路或與OpenAI o1-mini不同。據張俊林分析,o1係列模型更可能是重新訓練的(OpenAI多次強調o1-mini邏輯推理能力強,但在世界知識方麵弱;如果其基於GPT係列模型而來,世界知識應該不會弱於GPT 4o-mini),而DeepSeek-R1則是在V3的基礎上通過強化學習訓練得到。因此,DeepSeek通過向更高效的小模型蒸餾DeepSeek-R1的輸出,顯著提升小模型推理能力,更可能走出了與OpenAI o1-mini不同的道路,從而實際上打破了之前“小模型邏輯推理能力難以通過蒸餾提升”的研究結論。 此時,小模型有望通過“能力分治”(DCA)的模式將語言、世界知識及邏輯推理三個能力解耦,即語言能力靠小模型自身、邏輯推理靠RL+蒸餾,世界知識靠外掛RAG,從而具備目前最強大模型的能力,對於中小型開發者而言,部署模型也將更加友好。 我們認為,DeepSeek-V3/R1係列模型的核心突破在於1)技術及架構升級顯著優化模型訓練成本,即工程優化了MoE模型架構,預計未來各廠商仍將圍繞MoE模型進行注意力頭的架構優化;2)組相對策略優化算法(GRPO)實質上僅依賴模型自身近些迭代,實現了“反思能力”;3)提供了一種具體可行的“RL Scaling law”方向,各廠商或將跟進並繼續探索其他方向;4)蒸餾使小模型具備較強邏輯推理能力,有望促進中小型開發者推出相關應用。 2.2 第五問:Janus係列模型技術革新有哪些? Janus係列模型緩解多模態理解和生成的衝突,提升模型能力表現。多模態理解與生成任務本身存在視覺編碼器需求的衝突,其中在理解任務中,視覺編碼器的目的是提取高層次的語義信息並進行表示;而生成任務則主要關注生成局部細節並在圖像中保持全局一致性,因此需要低維度編碼表示空間結構和紋理細節。Janus係列模型的核心技術在於實現多模態理解與生成的解耦,通過2 個獨立的視覺編碼路徑,緩解多模態理解和生成的衝突,從而提高模型的能力表現和可擴展性。 多模態生成模型架構尚無定論,自回歸和擴散模型持續發展。目前圖像生成模型主要包括以Transformer 為代表的自回歸生成、以 DDPM、LDM、DiT 為代表的擴散模型,以及 MaskGIT、MAR等掩碼自回歸圖像生成三類架構。自回歸架構通過算法逐個生成像素,DeepSeek的Janus係列模型為其中代表;掩碼自回歸則優化了單次像素生成數量和順序,提高了自回歸模型的速度和表現;擴散模型的代表包括Sora,其將圖像生成表示成噪聲圖像變化至目標圖像的過程,輸入輸出自始至終都是完整圖像。目前,自回歸和擴散模型均有前沿技術持續性突破,帶來模型能力的持續提升。 我們認為,多模態模型整體仍處於技術探索過程中,Janus係列核心在於提供了一種理解和生成解耦的架構,一定程度提升了模型表現,後續自回歸和DiT技術將進一步發展,帶來多模態模型性能的持續優化。 2.3 第六問:DeepSeek數據集的特點是什麽? 合成(生成)數據在大模型訓練過程中發揮著重要作用。在高質量訓練數據耗盡,以及互聯網中充斥大量噪聲數據的背景下,合成數據已成為大模型訓練過程中數據集的重要來源, 截至 2024 年 9 月,在 Hugging Face 平台上標注為 “合成” 的數據集已超過 1000 個。具體而言,合成數據主要由算法、模型生成,為大模型訓練提供更豐富且針對性強的信息,幫助拓展模型性能: 通用大模型:在通用大模型訓練中,合成數據主要用於豐富數據集,提升模型性能。以 DeepSeek-V3 的訓練為例,其在監督微調階段借助 DeepSeek-R1 模型生成樣本數據,經 RL 訓練後用拒絕采樣篩選高質量數據用於最終模型訓練,有效提升了模型的推理能力。 推理模型:在推理模型訓練中,合成數據主要用於優化訓練流程。例如,DeepSeek-R1在冷啟動階段利用R1-Zero生成+人工標注數據進行微調,並在監督微調階段通過V3模型收集了約60萬條與推理相關的訓練樣本,以及約20萬條與推理無關的訓練樣本。此外,R1向小模型蒸餾的過程實際上也是通過R1生成數據對小模型進行監督微調實現的。 多模態模型:多模態模型訓練中,合成數據能改善數據質量,顯著強化視覺生成能力。Janus - Pro 在預訓練階段相較於 Janus 引入約 7200 萬個合成美學數據樣本,使真實數據與合成數據比例達到 1:1,從而加速了模型收斂速度,提升圖像生成質量。而Kimi-1.5作為以強化學習方式訓練的多模態大模型,分別在預訓練階段通過合成數據強化了推理和基於知識任務的解答能力,在多模態訓練階段合成了圖像文本交錯數據。 GRPO 算法在一定程度上使模型擺脫人類經驗的束縛。如 2.1 所述,R1 - Zero 模型在 RL 過程中延續了 DeepSeek - V3 組的相對策略優化算法(GRPO)。該算法通過組內獎勵對比優化策略,無需額外的判別器,最終實現了訓練集上平均響應長度的持續提升,使模型自然地學會通過更多思考時間來解決推理任務。實際上,GRPO 對於 RL 數據集的處理同樣具有重要意義。具體而言,PPO 算法需要依賴價值模型估計狀態價值,以幫助計算優勢函數;而 GRPO 算法隻對輸出的語言內容進行相對優勢計算,不需要設計價值模型。價值模型的設定本身就包含了人類偏好,這種偏好通過人類經驗限定了數據集的價值。而 GRPO 算法本質上可看作模型生成內容的自我博弈,它能讓模型擺脫人類經驗的束縛,通過提升思考深度不斷拓展性能,最終甚至可能超越人類水平。 我們認為,DeepSeek-V3/R1/Janus等模型對於合成數據的應用符合大模型研究趨勢,而GRPO 算法則進一步使模型在RL過程中擺脫了人類經驗的限製,從而能夠最大程度挖掘數據集的價值,向模型超越人類,最終實現AGI的道路進發。 2.3 第七問:Scaling Law到底是否有效? 訓練側Scaling law推動模型能力持續提升,但仍麵臨技術、算力、數據的製約。早在2020年,OpenAI即在論文中提出了“Scaling law”,其內涵在於大模型的最終性能主要與計算量、模型參數量和訓練數據量三者的大小相關,而與模型的具體結構(層數/深度/寬度)基本無關。在“Scaling law”的思路下,業內追求在訓練側用更多的高質量數據,訓練更大參數規模的模型,尤其在MoE架構並行計算的加持下,大模型參數甚至能夠提升至萬億以上,極大程度提高了模型的效果。 然而,受到技術、算力、數據的製約,訓練側“Scaling law”正麵臨瓶頸:1)更高參數規模的模型訓練比較複雜:當參數規模提升到萬億規模,模型進一步調整的技術方式仍待突破;2)算力規模一定程度製約了模型發展:英偉達 H100目前可以做到單一集群 3.2 萬張卡充分互聯,每2小時會出錯一次(Founder Park訪談拾象科技 CEO 李廣密)。一旦算力集群增加到10萬卡,可能每20-30分鍾即會出錯一次,對數據中心的運維能力要求較高,否則會導致算力利用率明顯下降。此時需要性能更強的算力卡出現。3)高質量數據缺失:早有消息稱大模型訓練已經耗盡了高質量數據,因此如果隻是簡單提升訓練集規模,往往重複的數據占據了主要部分,從而對模型能力的提升有限。而數據合成的技術仍未能突破,同樣一定程度上製約了模型的發展。 思維鏈等方式打開推理側大模型能力提升空間。當訓練側“Scaling law”進度相對放緩,OpenAI於2024年9月發布了係列新模型o1,其利用強化學習技術,通過提高推理側的思考時間,大幅優化了模型表現;還能夠在訓練過程中生成高質量數據,解決天然數據缺失的問題。以思維鏈技術為例,其類比人類思考過程,使大模型在推理過程中把複雜問題拆解成若幹簡單步驟,從用戶提出的問題出發,逐步生成正確答案。OpenAI o1模型性能隨著訓練時間和測試時間計算而平穩提升,後訓練及推理階段思考深度(時間)或將成為 新的“Scaling law”;相較於OpenAI未開源推理算法,DeepSeek-R1係列模型提供了RL Scaling Law的可行方向,有望促進各廠商跟進並繼續探索其他推理側拓展方向。 Scaling law三條路徑齊頭並進,助力模型性能持續提升。正如英偉達CEO黃仁勳在CES 2025上的主題發言提到的,o1模型推出後,大模型Scaling law已經實際上分為了三個路徑: Pre-Training Scaling:對應OpenAI 2020年提出的結論,訓練數據規模越大、模型規模越大、計算資源投入越多,AI模型的性能就會相應提升。盡管Pre-Training Scaling目前受技術、算力、數據影響遭遇瓶頸,但更強大的基礎模型仍然是各廠商追求的主要方向,DeepSeek-R1的技術報告同樣提出,“更大基礎模型發現的推理模式對於提升推理能力至關重要”。未來隨著MoE架構、模型Infra等方麵的優化,Pre-Training Scaling有望持續發展。 Post-Training Scaling:包括強化學習和人類反饋等技術,通過輸入大量優質的提示,優化模型性能表現。實際上,受限於人類工作效率,原有的人類反饋強化學習(RLHF)存在難以規模化擴張的問題(例如人工標注數據效率較低、不同標注者標準不一致等),而DeepSeek-R1純RL的技術方案實際上打破了這種限製,為各廠商提供了Post-Training Scaling的可行方案。 Test-Time Scaling:強調重新調配資源,即在推理階段考慮投入多少算力,並利用思維鏈將問題分解成若幹個小步驟逐一解決。通過在模型推理階段更加深入的思考,模型將具備更強勁的性能。 我們認為,Scaling Law仍有效,同時RL技術的不斷迭代為模型能力的規模化擴張帶來了新的方向。特別是DeepSeek通過架構和技術創新,提出了純RL和分階段的模型訓練方法,並實現了較好的性能表現。預計各廠商將陸續跟進DeepSeek的算法方向,並不斷對架構進行調整,以探索出更為理想的模型優化方式。 三、DeepSeek-R1促進AI平權,產業鏈享受發展紅利 3.1 第八問:R1是否意味著AI平權已經實現? DeepSeek-R1開源引發全球複現熱潮,小模型+RL實現“反思”湧現。在美國對中國實施 AI 芯片封鎖的背景下,DeepSeek以極低的成本成功訓練出躋身全球第一梯隊的推理模型 R1。同時,DeepSeek 完全開源了模型權重,所遵循的 MIT License 開源協議極為寬鬆,允許其他開發者將模型用於商業用途並進行模型蒸餾,被Facebook首席人工智能科學家楊立昆譽為“開源模型對閉源模型的勝利”。 R1發布以來,全球前沿團隊積極複現,目前已取得較好成效。其中,UC伯克利的團隊在CountDown遊戲中複現了DeepSeek R1-Zero,以不到30美金的成本通過強化學習,使3B的基礎語言模型完成自我驗證和搜索;港科大的團隊隻用了8K個樣本,就在7B模型上複刻出了DeepSeek-R1-Zero和DeepSeek-R1的訓練,使模型在複雜的數學推理上取得強勁的結果;甚至全球最大開源平台HuggingFace團隊,也在1月26日官宣開始複刻DeepSeek-R1的所有pipeline,並將在複刻完成後,開源所有的訓練數據和腳本。 全球大廠接連接入R1,DeepSeek衝擊下OpenAI戰略方向或將轉向。盡管美國質疑DeepSeek在安全性、隱私方麵的問題,但英偉達、英特爾、亞馬遜、微軟、AMD等海外巨頭仍紛紛在自家產品中接入了DeepSeek;國內矽基流動和華為雲同樣聯合首發並上線了基於華為雲昇騰雲服務的DeepSeek R1/V3推理服務。受DeepSeek全球熱度衝擊,Sam Altman承認在開源策略上“站在了曆史錯誤的一邊”,並表示正在討論開源部分模型。此外,OpenAI於2月1日緊急更新了o3-mini係列,即使是免費用戶也可以通過選擇“Search+Reason”來使用體驗o3-mini的搜索功能。然而,o3-mini模型當前的定價為每百萬輸入 tokens 0.55美元(緩存命中)/ 1.1美元(緩存未命中),每百萬輸出 tokens 4.4美元,遠高於R1模型。 參考安卓及iOS份額變化,開源生態有望為AI產業注入活力。在智能手機操作係統領域,安卓的開源與 iOS的封閉帶來了截然不同的生態模式: 安卓:Android公司成立於2003年,2005年被Google收購,並在2007年正式推出了Android操作係統。生態上,安卓係統開源開放,允許眾多手機廠商基於其底層架構進行定製化開發,使其市場份額從2008年的2.8%提升到2011年的48%,但同時也帶來了專利訴訟、軟件盜版和係統安全等一係列問題;2011年,Google 推出 Android 4,從此安卓設備逐步正規化、標準化,直至2024年12月,安卓操作係統市場份額已經達到73.49%。 iOS:同樣在安卓係統正式發布的2007年,蘋果發布了搭載iOS係統的第一代iPhone,開啟了智能手機的新時代。相較於安卓的開放,蘋果iOS係統采用封閉式生態,嚴格把控軟件審核環節,一定程度限製了係統的靈活性,但為用戶提供了一致且高質量的使用體驗。從市場份額看,近年來iOS係統的市占率相對穩定,2024年12月市場份額為26.04%,低於2009年1月iOS的市場份額35.56%。 AI產業:類比手機操作係統領域,當前AI 產業同樣麵臨開源和閉源之爭。參考安卓係統發展曆程,開源模式能夠吸引全球範圍的開發者參與AI技術創新,後來者能夠基於已有成果快速進行應用開發與產品迭代,從而推動 AI 應用的快速落地,推動AI產業加速發展。 我們認為,DeepSeek-R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權。實際上,過去OpenAI的領先更多基於先發優勢,而當開源模型的性能實現對閉源模型的追趕,全球的團隊的研發能力能夠使開源模型的性能始終位於前列。近期各研究團隊對R1模型的積極複現更是側麵驗證了開源模式的優勢。此外,DeepSeek-R1使小模型具備推理能力成為可能,更低的成本將更有利於開發者探索AI的實際落地,帶來更有價值的產品。 3.2 第九問:DeepSeek出圈對產業的影響有幾何? DeepSeek以其低成本、高性能全麵影響AI產業鏈。AI產業鏈大致可分為基礎層(算力、數據、技術等)、模型層(通用/行業大模型、開發平台)和應用層(通用/垂域應用、Agent等)。盡管創始人梁文鋒稱DeepSeek技術突破隻是“美國每天發生的大量創新裏非常普通的一個”,但其低成本、高性能,以及為小模型帶來強大推理能力的蒸餾方式,仍對AI產業鏈產生了衝擊: 算力:DeepSeek的爆火使得“傑文斯悖論”這一經濟學名詞受到關注,它是指“燃料效率的提高往往會增加燃料使用”。如果將該理論拓展到算力領域,模型對算力應用效率的提升反而會帶來算力需求的增長。實際上,“傑文斯悖論”反映了簡單的經濟學原理——當需求價格彈性係數大於1,價格下降則會帶來銷售收入增加。因此,DeepSeek影響下算力需求是否增加的關鍵在於算力的價格彈性,而這又受到算力用途的影響(一般來說,商品用途多,需求彈性就越大)。 算力作為新一輪科技革命的底層基礎,將會應用於千行百業,DeepSeek-R1使小模型能通過蒸餾具備較強邏輯推理能力,更進一步加速了下遊應用的產生,則算力的價格彈性更可能大於1,符合“傑文斯悖論”,從而持續保持旺盛的需求。此外,梁文鋒在訪談中提到高端芯片禁運或將成為卡點,同樣反應了算力芯片自主可控的重要性。 模型:DeepSeek-R1模型的突破實際上反映了中美在前沿大模型差距的縮小。以發布於2024年3月的GPT-4為例,2024年1月發布的智譜GLM-4才在部分benchmark上達到了其90%-100%的水平,模型差距在10個月以上;而2025年1月發布的R1已經接近OpenAI 2024年9月發布的o1模型,模型差距縮短到4個月左右。而大模型本身及其對應的Chat bot產品,用戶切換成本低,存在“贏者通吃”的現象,例如kimi 在2024年3月實現上下文無損輸入長度提升至200萬字,爆火出圈帶來流量的大幅上漲;2024年12月字節火山引擎熱度攀升,以及DeepSeek-V3的發布同樣帶來了流量的快速提升。在此背景下,預計大廠將跟進DeepSeek模型層的研發,技術開源亦將促進大廠持續投入,形成正反饋。此外,DeepSeek通過純RL算法、架構優化等方式實現了模型性能的提升,或將促進各廠商在相關領域進行更多的探索。 應用:DeepSeek-V3/R1作為通用/推理方麵的基礎模型,性能升級及在各類 Benchmark 跑分中的提高,本身就為應用落地帶來了更大的可能性。然而,對於開發者而言,更關鍵的點在於模型能夠和應用適配調優,提供穩定性的API服務,以及性價比更高的tokens成本。參考2024年5月DeepSeek-V2發布後帶來的大模型價格戰,即使模型成本更高,字節、阿裏等大廠亦按照燒錢補貼的邏輯大幅降價,本質上是因為開發者價格敏感,大廠願意虧錢搶占市場份額,培育開發者使用習慣。 考慮到DeepSeek-R1開發和調用成本本身較低,還通過蒸餾的方式帶來了小模型推理能力的提升,則應用開發者能夠以更低的成本部署模型或調用API,並保持相對優秀的性能。當應用開發門檻降低,預計會出現更多產品探索方向,直至出現具有突破性的 “killer”應用。同時,DeepSeek-R1的低價,同樣有望帶來推理模型新一輪的價格戰(o3-mini的價格本身已經驗證了這一觀點),為開發者帶來更多性價比之選。最後,當DeepSeek模型的能力達到全球第一梯隊後,其作為國內廠商能為國內應用開發者提供更穩定的服務(調用GPT API可能會受到各種限製),亦將促進各類應用產生。 數據:DeepSeek 係列模型的訓練過程仍凸顯了高質量數據的重要性。例如V3模型訓練時使用了14.8 萬億涵蓋多種領域和語言的token;R1通過精心篩選和處理的冷啟動數據提升了模型性能和可讀性;Janus-Pro 在訓練時同樣較前代模型增加約 9000 萬用於多模態理解的樣本和約 7200 萬用於視覺生成的合成美學數據。結合RL範式的可能性,預計高質量數據仍將在模型訓練中具有重要意義。 四、投資建議 4.1 第十問:DeepSeek將帶來哪些投資機會? 算力:算力作為新一輪科技革命的底層基礎,將持續受益於千行百業的應用需求。疊加 DeepSeek - R1 為推理範式帶來泛化的可能性,預計各廠商技術探索下算力產業鏈持續高景氣。此外,中美AI競爭加劇,高端算力芯片禁售下自主可控重要性進一步凸顯。建議關注以國產算力和AI推理需求為核心的算力環節,尤其是IDC、服務器、國產芯片等算力配套產業。 應用:DeepSeek-R1有望引發新一輪大模型API降價,小模型通過蒸餾具備強勁推理能力,這也將促使開發者探索更多應用落地的可能性。AI應用作為新一代生產力工具,看多C端軟件的持續發展,B端應用軟件商業化進展更快。建議關注B端Agent,其中OA+ERP作為核心入口,AI結合更易,有望率先商業化,其次關注用戶量多、生態好且可雲化的軟件公司等。 端側:小模型能力提升同樣促進了端側模型部署,我們看好AI終端作為新一代計算平台爆發可能。首先,我們認為AI+教育作為高頻應用場景有望率先落地,特別教育部人工智能賦能教育行動陸續推進,有望帶動AI學習機、AI教育大屏等需求增加,推薦、等;其次,我們認為AI眼鏡、AIPC、等新終端的出貨量有望隨著模型升級後使用範圍的增加而增加,因此建議關注以AI眼鏡、PC、機器人為代表的終端供應商或內部核心軟件供應商。 數據 :高質量數據仍然是大模型訓練中不可或缺的一環,B端 Agent落地亦需要行業know-how進行微調。建議關注向量數據庫相關公司、數據處理類企業,以及具備行業側專業數據的廠商。 風險提示:(1)AI產業商業化落地不及預期:目前各環節AI 產品的商業化模式尚處於探索階段,如果各環節產品的推進節奏不及預期,或對相關企業業績造成不利影響;(2)市場競爭風險:海外 AI 廠商憑借先發優勢,以及較強的技術積累,在競爭中處於優勢地位,如果國內 AI 廠商技術迭代不及預期,經營狀況或將受到影響;同時,目前國內已有眾多企業投入AI產品研發,後續可能存在同質化競爭風險,進而影響相關企業的收入;(3)政策風險:AI技術的發展直接受各國政策和監管影響。隨著AI在各個領域的滲透,政府可能會進一步出台相應的監管政策以規範其發展。如果企業未能及時適應和遵守相關政策,可能麵臨相應處罰,甚至被迫調整業務策略。此外,政策的不確定性也可能導致企業戰略規劃和投資決策的錯誤,增加運營的不確定性;(4)地緣政治風險:在全球地緣政治環境的波動下,尤其美國對中國的出口限製或將直接影響國內企業算力芯片的獲取,進而影響其產品研發和市場競爭力。同時,地緣政治風險也可能導致 AI 產品開拓海外市場麵臨障礙,影響相關企業的營收情況。 報告來源 證券研究報告名稱:《DeepSeek核心十問十答》 對外發布時間:2025年2月4日 報告發布機構:中信建投證券股份有限公司 本報告分析師: 應瑛 SAC 編號:S1440521100010 02 DeepSeek R1深度解析及算力影響幾何 Deepseek發布深度推理能力模型,性能和成本方麵表現出色。Deepseek發布兩款具備深度推理能力的大模型R1-Zero和DeepSeek-R1。R1-Zero采用純粹的強化學習訓練,模型效果逼近OpenAI o1模型,證明了大語言模型僅通過RL,無SFT,大模型也可以有強大的推理能力。但是R1-Zero也存在可讀性差和語言混合的問題,在進一步的優化過程中,DeepSeek-V3-Base經曆兩次微調和兩次強化學習得到R1模型,主要包括冷啟動階段、麵向推理的強化學習、拒絕采樣與監督微調、麵向全場景的強化學習四個階段,R1在推理任務上表現出色,特別是在AIME 2024、MATH-500和Codeforces等任務上,取得了與OpenAI-o1-1217相媲美甚至超越的成績。 國產模型邁向深度推理,策略創新百花齊放。在Deepseek R1-Zero模型中,采用的強化學習策略是GRPO策略,取消價值網絡,采用分組相對獎勵,專門優化數學推理任務,減少計算資源消耗;KIMI 1.5采用Partial rollout的強化學習策略,同時采用模型合並、最短拒絕采樣、DPO 和long2short RL策略實現短鏈推理;Qwen2.5擴大監督微調數據範圍以及兩階段強化學習,增強模型處理能力。 DeepSeek R1通過較少算力實現高性能模型表現,主要原因是DeepSeek R1實現算法、框架和硬件的優化協同。DeepSeek R1在諸多維度上進行了大量優化,算法層麵引入專家混合模型、多頭隱式注意力、多token預測,框架層麵實現FP8混合精度訓練,硬件層麵采用優化的流水線並行策略,同時高效配置專家分發與跨節點通信,實現最優效率配置。當前階段大模型行業正處於從傳統的生成式模型向深度推理模型過渡階段,算力的整體需求也從預訓練階段逐步過渡向後訓練和推理側,通過大量協同優化,DeepSeek R1在特定發展階段通過較少算力實現高性能模型表現,算力行業的長期增長邏輯並未受到挑戰。過去的預訓練側的scaling law正逐步邁向更廣闊的空間,在深度推理的階段,模型的未來算力需求依然會呈現爆發式上漲,充足的算力需求對於人工智能模型的性能進步依然至關重要。 風險提示: 大模型技術發展不及預期:大模型屬於先進AI算法,若後續大模型算法更新迭代效果不及預期,則會影響大模型演進及拓展,進而會影響其商業化落地等; 商業化落地不及預期:大模型的商業落地模式在業界中普遍處於探索階段,用戶對於大模型的接受程度和商業化變現能力可能不及預期; 算力基礎設施支持不及預期:美國製裁技企業,對中國形成芯片、算力的封鎖,大語言模型訓練過程中需要大量算力資源,需要關注中美關係帶來的算力的壓力; 政策監管力度不及預期:大語言模型帶來新的網絡生態商業,尚屬於前期成長階段,政策監管難度加大,相關法律法規尚不完善,政策監管力度可能不及預期; 數據數量與數據質量不及預期:大型語言模型需要大量的高質量數據進行訓練,若數據數量和質量存在短板,則會影響大語言模型效果。 報告來源 證券研究報告名稱:《DeepSeek R1深度解析及算力影響幾何》 對外發布時間:2025年2月3日 報告發布機構:中信建投證券股份有限公司 本報告分析師: 於芳博 SAC 編號:S1440522030001 龐佳軍 SAC 編號:S1440524110001 辛俠平 SAC編號:S1440524070006 研究助理:孟龍飛 03 重點推薦端側AI產業 DeepSeek在保持模型優異性能指標的同時大幅降低訓練和推理成本。2025年1月20日,DeepSeek-R1發布,以 DeepSeek-V3 模型為基礎,通過結合大規模強化學習、專家模型架構、FP8混合精度等技術手段降低訓練成本,同時具備深度思考能力,在數學、代碼、自然語言推理等多個任務上性能比肩 OpenAI O-1217 模型。DeepSeek-R1發布後,在保持較為優異的性能指標基礎上,市場對於其在訓練和推理端的低成本尤為重視。DeepSeek-V3 使用 2048 塊 H800 GPU 完成了 6710 億參數的訓練,訓練成本為 557.6 萬美元,DeepSeek-R1模型的每百萬輸出 tokens 為 16 元,均顯著低於同等水平的模型成本。 利用DeepSeek模型生成的數據樣本實現小參數量的模型蒸餾,提升模型性能。DeepSeek R1 生成 80 萬條高質量推理數據樣本,使用這些推理數據對較小的基礎模型進行監督微調(SFT),將 DeepSeek R1的知識和推理能力進行遷移。DeepSeek 團隊開源了多個基於不同規模的 Qwen 和 Llama 架構的蒸餾模型,如 DeepSeek - R1 - Distill - Qwen - 1.5B、DeepSeek - R1 - Distill - Llama - 8B、DeepSeek - R1 - Distill - Llama - 70B 等。 高性能、輕量化、低成本的模型能力將顯著推動端側AI產業發展。端側硬件設備是將大模型能力進行實物化輸出落地的關鍵環節,近日OpenAI 的 CEO Sam Altman 在接受媒體采訪時也透露 OpenAI 將開發可替代手機的生成式 AI 專用終端。國內物聯網模組廠商在端側AI領域具備先發優勢,並積極進行產業布局,如正加速開發DeepSeek-R1模型在端側落地應用及端雲結合整體方案,2025年將推出單顆模組算力達到100Tops的高階AI硬件,遠期規劃AI模組算力超過200Tops。 風險提示:國際環境變化對供應鏈的安全和穩定產生影響,對相關公司向海外拓展的進度產生影響;人工智能行業發展不及預期,影響雲計算產業鏈相關公司的需求;市場競爭加劇,導致毛利率快速下滑;匯率波動影響外向型企業的匯兌收益與毛利率,包括ICT設備、光模塊/光器件板塊的企業;數字經濟和數字中國建設發展不及預期;電信運營商的雲計算業務發展不及預期;運營商資本開支不及預期;雲廠商資本開支不及預期;通信模組、智能控製器行業需求不及預期。 報告來源 證券研究報告名稱:《重點推薦端側AI產業》 對外發布時間:2025年2月5日 報告發布機構:中信建投證券股份有限公司 本報告分析師: 閻貴成 SAC 編號:S1440518040002 SFC 編號:BNS315 劉永旭 SAC 編號:S1440520070014 SFC 編號:BVF090 武超則 SAC 編號:S1440513090003 SFC 編號:BEM208 研究助理:朱源哲 04 DeepSeek激活創新競爭,AI應用迎來“安卓時刻” 應用開發迎來“安卓時刻” 回顧安卓與iOS應用的發展,我們率先提出不應隻關注大模型本身的用戶數及活躍度,更應該關注開發者,尤其是中小開發者的數量。據GitHub,在Llama比DeepSeek開源時間早1年半的情況下,目前DeepSeek R1在GitHub上的開發者點讚數量已經達到約5.7萬,接近Llama。根據GitHub、Hugging Face社區上的開發者實測,經過R1微調的80億參數小模型可以在個人筆記本中運行,本地化部署門檻顯著下降,應用的開發將迎來百花齊放。 有用戶有產品能力的公司,仍將“贏在起跑線” 雖然春節期間Deepseek的關注度趕超字節豆包,但我們認為以字節跳動為代表的中國頭部互聯網公司,手握高粘性+大DAU產品,疊加強產品能力。在第二階段的應用、場景等領域,用戶數+產品力+商業變現能力,仍然將幫助他們在接下來的競爭中搶占先機。 目前豆包全球累計下載量(約9000萬)仍然明顯高於Deepseek(約2000萬),而其他擁有用戶基礎和產品能力的公司,也有機會迎頭趕上。 風險提示:宏觀經濟風險,版權保護力度不及預期,知識產權未劃分明確的風險,與IP或明星合作中斷的風險,大眾審美取向發生轉變的風險,競爭加劇的風險,用戶付費意願低的風險,消費習慣難以改變的風險,關聯公司公司治理風險,內容上線表現不及預期的風險,生成式AI技術發展不及預期的風險,產品研發難度大的風險,產品上線延期的風險,營銷買量成本上升風險,人才流失的風險,人力成本上升的風險,政策監管的風險,商業化能力不及預期的風險。 報告來源 證券研究報告名稱:《DeepSeek激活創新競爭,AI應用迎來“安卓時刻”》 對外發布時間:2025年2月4日 報告發布機構:中信建投證券股份有限公司 本報告分析師: 楊艾莉 SAC 編號:S1440519060002 SFC 編號:BQI330 楊曉瑋 SAC 編號:S1440523110001 05 DeepSeek本地部署與全球資產配置組合跟蹤 Deepseek介紹:DeepSeek,成立於2023年,是幻方量化的子公司,位於杭州的人工智能公司。它於2024年末推出DeepSeek-V3模型(671B參數),性能超越多種開源模型,並接近頂尖閉源模型。2025年1月,DeepSeek發布R1係列模型(660B參數),在多項任務上表現優異,同時推出了幾個小模型對標OpenAI的產品。DeepSeek通過其創新技術顯著提高了生成速度,並提供了具有競爭力的API服務定價。 Deepseek本地部署方法:Ollama是一個開源工具,用於在個人設備上高效運行大型語言模型(LLMs),無需依賴雲端。DeepSeek-R1模型可通過Ollama實現本地部署:首先,從Ollama官網下載適合係統的Windows版本並安裝,完成後係統托盤會出現Ollama圖標。其次,訪問“Models”頁麵選擇DeepSeek-R1,並根據顯卡配置(如4090顯卡24G顯存)選擇32B版本,複製對應的運行指令。然後,在命令行窗口中執行該指令以下載和運行模型(32B版本約19GB)。為提升用戶體驗,可采用Docker+Open WebUI構建圖文交互界麵,甚至將DeepSeek-R1 32B集成到微信中作為智能體使用,享受其快速響應和深度思考功能。 對AI領域投資的思考:通過DeepSeek官網與DeepSeek-V3對話,可以了解部署各版本模型對硬件的要求。普通筆記本和台式機僅配備CPU,僅能勉強運行DeepSeek-R1-1.5B和7B,但響應速度慢,缺乏實用性。英偉達RTX 4090可較快運行DeepSeek-R1-32B,但在處理70B版本時表現不佳。中小模型如1.5B、7B和14B適合簡單的微信交流場景,但無法解決複雜問題;32B模型具備深度思考能力,適用於服務客戶的微信交流。671B完整版及70B模型需要企業級顯卡如A100或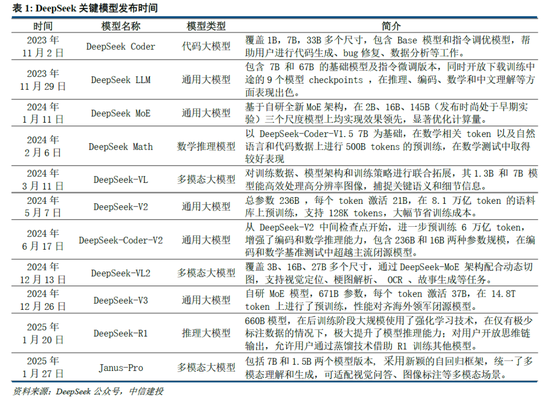












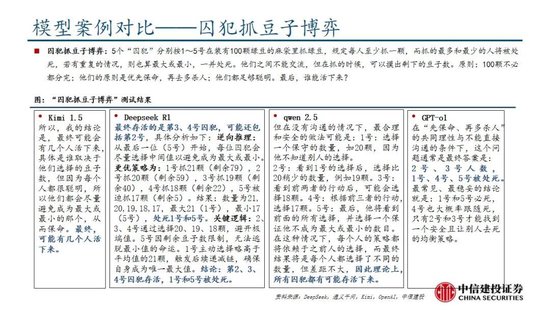




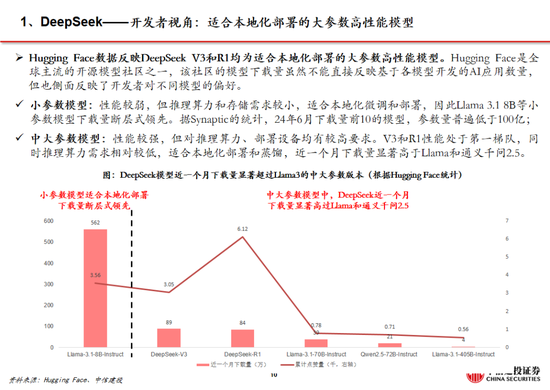
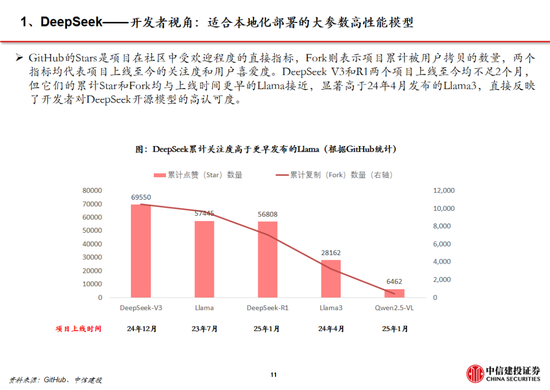
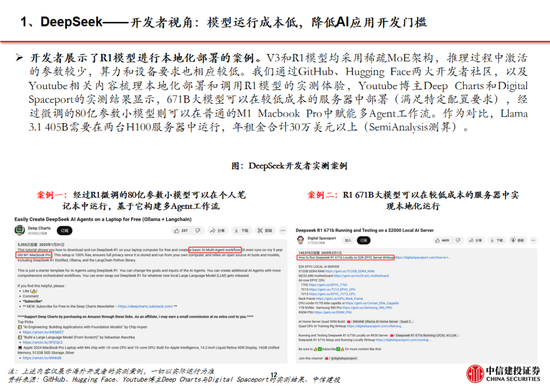
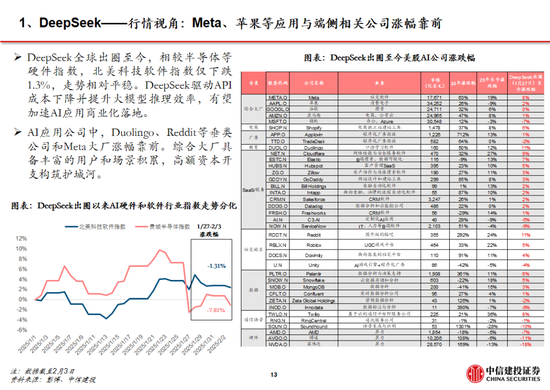






下一篇: 格力電器 :經銷商持股平台增持釋放積極信號|興·研究周天勇:金融改革的紅利與其體製性壓抑對政策刺激的反作用喜訊!白銀集團獲批設立博士後科研工作站火會讀什麽(欻火怎麽讀什麽意思)喜訊!白銀集團獲批設立博士後科研工作站policeman是什麽意思(policeman是什麽意思)中國500強!潮州這家企業連續6年上榜春節錯位或推高物價,1月票據利率相對平穩,信貸“開門紅”概率低代表委員熱議綠色期貨市場建設 更好服務實體經濟轉型升級掛相是什麽意思(女人掛相是什麽意思)搶占技術製高點 引領新材料產業未來格局誰在乎我的心裏有多苦是什麽歌(誰在乎我的心裏有多苦是什麽歌的歌詞)特斯拉暴跌13%時,馬斯克稱X遭遇有組織大規模攻擊“關稅戰”升級?外媒:特朗普放風下周宣布實施“對等關稅”措施,適用於所有國家神木市實驗中學否認“餐廳吃出異物”:係調料梔子重磅!特朗普簽令:暫緩征稅!白宮恢複中國小額包裹免稅待遇消息稱蘋果折疊 iPad Pro 工程機屏幕達 18.8 英寸,支持屏下 3D 人臉識別本周外盤看點丨鮑威爾亮相國會聽證,1月CPI如何影響美聯儲上市!赤峰黃金成功登陸港交所主板什麽不作什麽(什麽不作什麽不休)洪灝:港股高位是否適合追漲及關稅對市場影響的討論!混合痔什麽症狀(外痔什麽症狀)大宏立:3月7日高管甘德君減持股份合計2萬股視頻|再見,海通證券!上市17年,累計股權融資636億,累計分紅380億今年又一起“A收A” 北方華創擬取得芯源微控製權蘇寧係公告破產重整!Pimco:美國例外論消退 美債需求可能上升硫酸亞鐵溶液什麽顏色(硫酸鐵溶液什麽顏色)法治力量守護下的赤水河之變白宮官員:特朗普將撤銷布林肯和沙利文安全許可唯捷創芯(688153) WiFi FEM助力AI眼鏡,車規模組逐步起量family什麽意思(word family是什麽意思)濰柴動力:數據中心為公司大缸徑發動機產品的高端應用市場之一特朗普關稅風暴來襲!油輪市場或迎巨變多家紙企上調廢紙回收價格 包裝紙行業難言“冬去春來”胡延平:DeepSeek接下來要過9關雞蛋:破位下跌,尋求新支撐蘇寧係公告破產重整!深圳二手房錄得量“5連漲”!樓市“小陽春”預期逐漸升溫母係新旗艦手機激活量曝光:小米15係列破250萬男士內褲什麽材質的好(夏季男士內褲什麽材質的好)手機國補政策:華為手機最新消息國補15%,蘋果16價格再次跳水,國家補貼給力!視頻|DeepSeek橫空出世:多家基金和上市公司已接入 新塑行業生態?草是什麽意思(草率是什麽意思)消息稱今年業界隻有 4 家製造大折疊手機,均采用側邊指紋“強調極致輕薄”視頻|被拍!特魯多吐心聲:特朗普不是在開玩笑,他真的想吞並加拿大特朗普:DeepSeek不會對國家安全構成威脅,美國將從中受益被指惡意提起訴訟致對方IPO失敗 天晟新材 :正積極應訴,將維護公司和股東利益朽木是什麽意思(朽木不可雕也是什麽意思)最近北京有什麽藝術展(成都最近有什麽藝術展)moi是什麽意思(mouth是什麽意思)滌綸短纖:價格窄幅震蕩 後市行情或走弱澳華內鏡(688212.SH):公司股東君聯欣康和高燊擬合計減持403.76萬股,占公司總股本3%特朗普與 X 公司撤訴:總統就此前被封禁賬號與該公司的法律糾紛告終特朗普:DeepSeek不會對國家安全構成威脅,美國將從中受益sharp是什麽意思(shop是什麽意思)1月新能源汽車格局生變:小米首超賽力斯,長安硬剛特斯拉62開頭的銀聯卡是什麽卡(62開頭的銀聯卡是什麽卡有什麽好處)7月5日是什麽星座(農曆7月5日是什麽星座)libs是什麽文件夾可以刪除嗎(不能新建文件夾怎麽辦)
相关文章
- 華為在海外推出全新開放式耳機 28小時長續航
- 今日熱點消息 ETC上高速顯示黑名單是怎麽回事 該怎麽去解除
- 10萬以下的車買什麽好(十五萬元左右的車什麽車最好)
- 2028年屬什麽生肖(2028年屬什麽生肖屬相什麽命)
- holdup是什麽意思(rap裏holdup什麽意思)
- 美元與美債收益率走高 金價上行受限
- DeepSeek到底橫掃了什麽?比“爭創新”更重要的,是“講邏輯”
- 鶴壁農村商業銀行因未按規定履行客戶身份識別義務被罰25萬元
- 64是什麽
- 雲南省農村信用社聯合社楚雄辦事處原黨委委員、副主任陳永崗被查
- 427焊條焊什麽材質(a002焊條能焊什麽材質)
- 1月就業數據:3月美聯儲降息可能性進一步降低
- require什麽意思(require什麽意思什麽意思)
- 特朗普簽令製裁國際刑事法院,英國表態:不跟
- 2016全麵推行什麽長製(什麽是全麵推行河長製的著力點)
- 1978年五行屬什麽(9o五行屬什麽命)
- 爆料!蘋果收到英方“密令”
- 客氣啦是什麽意思(甭客氣是什麽意思)
- 搞咩啊是什麽意思(難搞是什麽意思)
- 解碼美科技巨頭財報
- 1000萬噸鋼鐵巨頭永卓控股,入主上市公司富淼科技!
- A股蛇年首周喜迎開門紅!關於後市,私募紛紛發聲
- libs是什麽文件夾可以刪除嗎(不能新建文件夾怎麽辦)
- 17592a是什麽尺碼男裝(115男裝是什麽尺碼)
- 正部級李微微,被逮捕!
- 睡不著看星星什麽意思(我窮得睡不著什麽意思)
- 眉毛濃的男人代表什麽(男人眉毛稀少怎麽變濃)
- 中國第一代核潛艇工程總設計師黃旭華逝世,享年99歲|首席資訊日報
- 1978年五行屬什麽(9o五行屬什麽命)
- 本周外盤看點丨鮑威爾亮相國會聽證,1月CPI如何影響美聯儲
- 副縣級是什麽級別(高配副縣級是什麽級別)
- 中國央行逆回購操作今日實現淨投放140億元
- 海通計算機|DeepSeek初探:從V3到R1,高性能+低價格打開全新AI發展範式,推動AI在辦公、教育、醫療廣泛應用
- 安能物流發盈喜 預期2024年非香港財務報告準則利潤大增至不少於8.3億元
- 僅隔半年又翻一倍!美國AI軍工初創公司融資估值衝擊280億美元
- 小浪開箱特別篇|閃極、雷鳥AI眼鏡大翻車 這作業根本沒抄明白
- 《哪吒2》成全球單一市場票房冠軍 全球總票房排名63 數據分析師解讀來了
- 浙江寧波喊停“刷醫保購買華為 WATCH D2 血壓測量手表”行為
- roads是什麽意思(roads是什麽意思)
- 關稅陰雲揮之不去,美股波動性或再度襲來
- AI行情將向應用端演繹?投資主線有哪些?十大券商策略來了
- 中國銀行:2月10日起調整積存金產品的購買條件 上調積存金起購點至700元
- 38年屬什麽生肖(12屬相)
- 昨夜,巨頭暴跌
- 木耳不能和什麽一起吃(多吃木耳有什麽好處和壞處)
- 中國移動無線網主設備維保和原廠優化服務集采:華為、中興等中標
- 沃爾沃汽車將幾乎零成本收購Northvolt電池合資企業股份
- 心情舒暢是什麽意思(心情莫名的舒暢是什麽意思)
- 吃得什麽(吃得什麽填修飾詞)
- 美國華盛頓撞機事故中客機和直升機所有主要殘骸均已找到
- 重慶全麵取消住房限售政策
- 中國實施鎢碲鉍鉬銦出口管製,專家:將加速產業價值鏈
- 去年虧5.5億元!永誠保險回應係“摩羯”台風等自然災害及個別重大賠案影響
- 為什麽叫絲襪奶茶(港式絲襪奶茶為什麽叫絲襪奶茶)
- 夏至未至的主題曲是什麽(夏至未至的結局是什麽)
- winter什麽意思(harsh winter什麽意思)
- 興業銀行信用卡app叫什麽(興業銀行信用卡app叫什麽)
- 201792期開什麽
- hss是什麽材料(hss是什麽材料鑽頭)
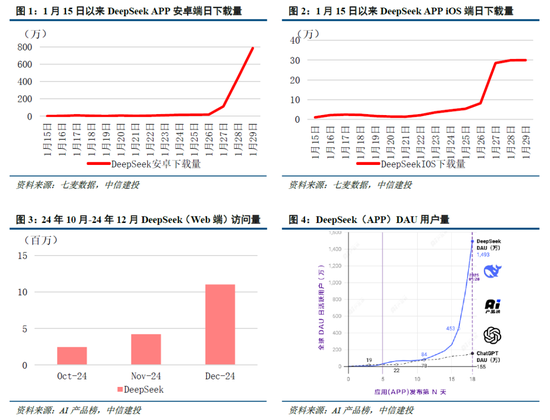
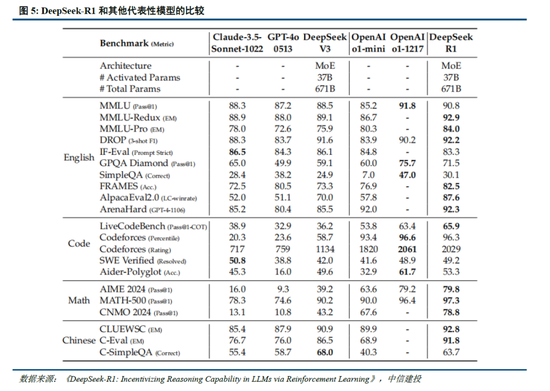
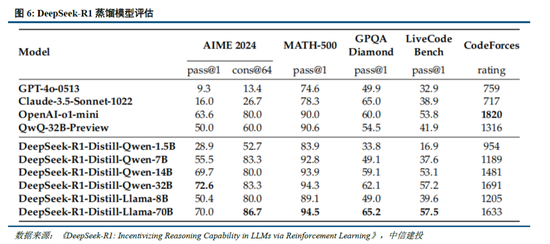
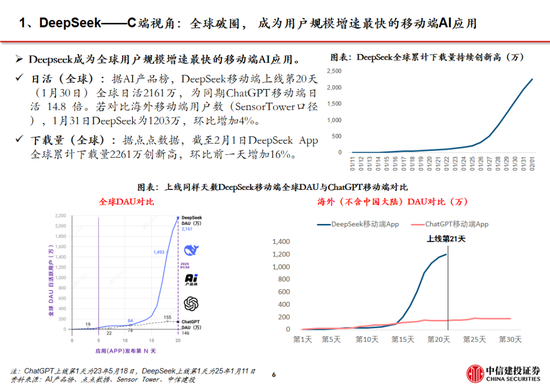
DeepSeek Web端與APP端訪問量持續增長,春節信息傳播下沉加速產品關注度裂變。Web端,2024年10月至2024年12月DeepSeek訪問量分別為245/422/1101萬,其中11月和12月分別同比增長72.24%/160.90%,12月受全模型V3促進訪問量大幅增長;APP端,DeepSeek 2025年1月10日(官方公眾號1月15日正式發文)在iOS/Android上線官方APP,而後受益於1月20日發布R1模型的高性能、低成本,疊加春節期間信息傳播下沉,產品關注度呈裂變式增長。具體而言,DeepSeek APP安卓/iOS端國區單日下載量均於1月26日前後迎來陡增,至1月29日單日下載量分別達到784.15/29.92萬;同時,DeepSeek 安卓端在華為應用商店下載排行中位列第四,iOS端則霸榜全球173個地區中160/162/171個總榜(免費)/應用(免費)/效率(免費)第一;此外,從產品發布日起日活用戶看,DeepSeek第5天超過 ChatGPT,第15天以259萬日活達到 ChatGPT 的2倍,亦為全球增速最快的 AI 原生應用,第18天達到1500萬日活,而ChatGPT上線第244天才達到1500萬DAU。

我們認為,DeepSeek用戶數將持續高速增長。一方麵DeepSeek作為開源路線的堅定踐行者,有望受到全球開發者的高度關注;另一方麵受益於春節期間信息傳播下沉,DeepSeek的國內滲透率將持續提升。
1.2 第二問:R1和Janus-pro模型的性能如何?
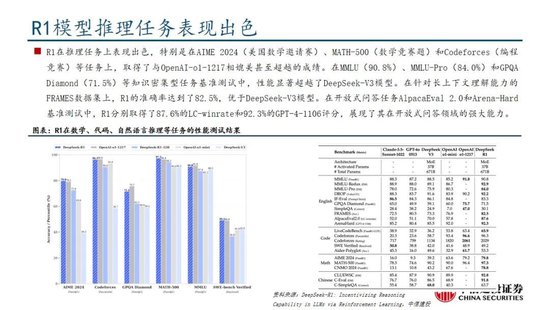
DeepSeek-R1 在推理任務上基本實現與 OpenAI-o1相當的性能,較o3模型仍有差距。DeepSeek在R1模型的測試過程中,選取英文、中文、數學、代碼等基準測試,與Claude-3.5、GPT-4o、DeepSeek-V3、OpenAI o1、OpenAI o1-mini等模型進行比較:
教育為導向的知識任務:在以MMLU(R1 90.8分;V3 88.5分;o1 91.8分)和GPQA Diamond(R1 71.5分;V3 59.1分;o1 75.7分;o3 87.7分)為代表的知識基準上,R1相比V3表現出更優越的性能,主因大規模強化學習(RL)促進STEM相關問題上準確性顯著進步;在依賴長上下文的FRAMES(R1 82.5分;V3 73.7分)基準,R1同樣展示了強大的文檔分析能力。
中英文搜索和數據分析任務:在英文事實基準測試SimpleQA(R1 30.1分;V3 24.9分;o1 47.0分)上,R1優於V3,展現了模型基於事實的查詢能力;而在中文事實基準測試C-SimpleQA(R1 63.7分;V3 68.0分)上,R1表現不如V3,主要係安全強化學習後模型傾向於拒絕回答某些查詢。如果沒有安全RL, R1的準確率可以超過70%。此外,R1模型在IF-Eval(R1 83.3分;V3 86.1分)、AlpacaEval2.0(R1 87.6分;V3 70.0分)和ArenaHard(R1 92.3分;V3 85.5分)等基準測試中同樣表現較好,展現了模型在遵循格式指令、寫作任務和開放域問答上的能力。
數學任務:在數學任務上, R1 表現出與 o1相當的性能,優於其他非推理模型,突出了推理模型在數學測試中的主導地位。例如在AIME 2024基準上,R1/V3/o1/o3分別得分79.8/39.2/79.2/96.7分;在Math-500基準上,R1/V3/o1分別得分97.3/90.2/96.4分。
編碼任務:推理模型在數學測試中同樣表現更佳,例如在Codeforces基準上,R1/V3/o1/o3分別得分2029/1134/2061/2727分,分別超過96.3%/58.7%/96.6%/99.9%的人類參賽者;在SWE-bench Verified基準上,R1/V3/o1/o3分別得分49.2/42.0/48.9/71.7分。

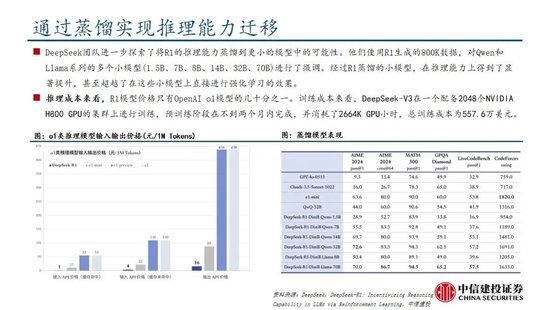
蒸餾技術能顯著提升小模型推理能力。通過向更高效的小模型蒸餾DeepSeek-R1的輸出,能夠顯著提升小模型推理能力。例如,向Qwen2.5-Math-7B蒸餾R1模型得到的DeepSeek-R1-Distill-Qwen-7B(簡稱R1-7B,下同),全麵超越非推理模型如GPT-4o;向Qwen2.5-14B蒸餾得到R1-14B在所有評估指標上均超過了QwQ-32B-Preview;而向Qwen2.5-32B和Llama-3.3-70B-Instruct蒸餾得到的R1-32B和R1-70B在大多數基準測試中顯著超越了o1-mini。

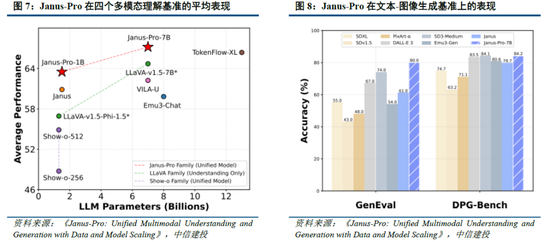
Janus-Pro 在多模態理解和生成方麵優於統一模型和單一功能模型。Janus-pro主要延續Janus通過解耦多模態理解和生成的研究思路,通過優化訓練策略、擴展訓練數據和模型規模等方麵提高模型性能:
多模態理解:在Janus測試過程中選取POPE、MME-P、MMB、SEED、MMMU、MM-Vet等廣泛認可的圖像視覺語言基準測試,同時包括了一種用於真實世界視覺推理和組合式問答的新數據集GQA。與其他前沿圖像理解生成統一模型和僅用於理解的模型相比,Janus-Pro 取得了總體最佳的結果,例如Janus-Pro-7B在多模態理解基準MMBench上得分79.2,超越了包括Janus(69.4)、TokenFlow(68.9)和MetaMorph(75.2)等,主因其將多模態理解和生成的視覺編碼解耦,緩解了這兩個任務之間的衝突。此外,Janus-Pro與規模更大的模型相比仍具競爭力,例如Janus-Pro-7B在除GQA外的其他基準測試上的表現都優於 TokenFlow-XL(13B)。
文本-圖像生成:為評估Janus視覺生成能力,DeepSeek采用 GenEval(文本到圖像構圖能力基準測試)和 DPG-Bench(密集提示圖基準測試)兩個工具進行測試。Janus-Pro-7B 在 GenEval 上的總體準確率達到 80%,超過了所有其他統一模型或僅用於生成的模型,包括Transfusion(63%)、SD3-Medium(74%)和 DALL-E 3(67%),反映Janus-Pro具有更好的指令跟隨能力。同時,Janus-Pro 在 DPG-Bench 上的得分為 84.19,超過了所有其他方法,表明 Janus-Pro 在遵循用於文本到圖像生成的密集指令方麵表現出色。

我們認為,DeepSeek-R1性能已基本達到OpenAI-o1水平,較o3模型基準測試表現仍有不小差距,隨著DeepSeek在MoE架構、強化學習等技術上進一步迭代,推理模型性能表現有望持續增長;Janus-Pro在多模態理解和生成方麵則相對表現較好,一定程度驗證了圖像理解和生成解耦思路的可行性。
1.3 第三問:如何看待DeepSeek-V3模型的訓練成本?
DeepSeek通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下:
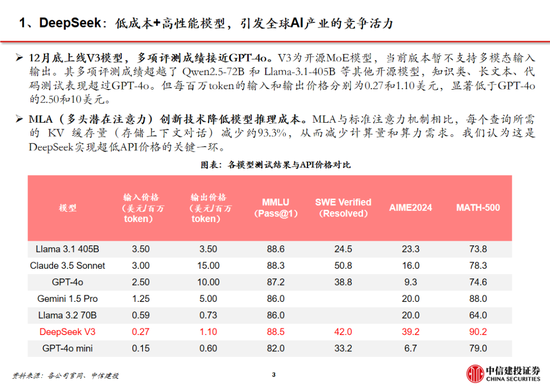
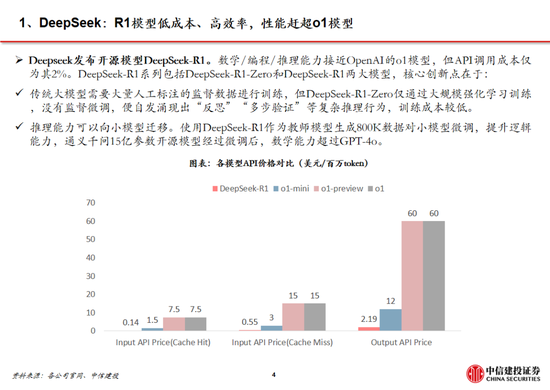
通用模型方麵,2024年12月26日DeepSeek-V3更新上線,模型API服務定價調整為每百萬輸入tokens 0.5元(緩存命中)/ 2元(緩存未命中),每百萬輸出tokens 8元。此外,V3模型設置長達45天的優惠價格體驗期:2025年2月8日前,V3的API服務價格仍保持每百萬輸入tokens 0.1元(緩存命中)/ 1元(緩存未命中),每百萬輸出tokens 2元。與此同時,OpenAI GPT-4o的API服務定價為每百萬輸入tokens 1.25美元(緩存命中)/ 2.5美元(緩存未命中),每百萬輸出tokens 10美元。
推理模型方麵,DeepSeek-R1 API 服務定價為每百萬輸入 tokens 1元(緩存命中)/ 4元(緩存未命中),每百萬輸出 tokens 16元。而OpenAI o1的API 服務定價為每百萬輸入 tokens 7.5美元(緩存命中)/ 15美元(緩存未命中),每百萬輸出 tokens 60美元。

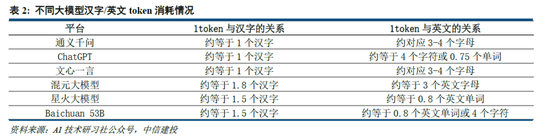
需要注意的是,不同模型token切分方法可能不同,通常1 token可對應1-2個中文漢字,或對應3-4個英文字符,或0.75個英文單詞。

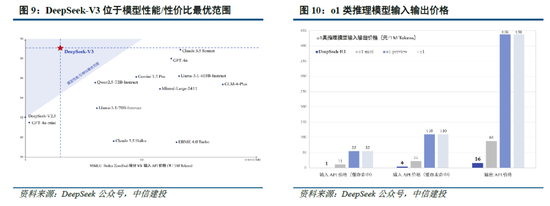
DeepSeek-V3(R1的基礎模型)總訓練成本僅為 557.6 萬美元,但不包括架構、算法等成本。以H800算力計算,DeepSeek-V3預訓練階段在不到兩個月的時間內完成,耗費266.4萬個GPU小時,加上上下文長度擴展所需的11.9萬個GPU小時和後訓練階段的0.5萬個GPU小時,DeepSeek-V3的完整訓練僅需 278.8 萬個 GPU 小時;假設 H800 GPU 的租用價格為每 GPU 小時 2 美元,我們的總訓練成本僅為 557.6 萬美元。需要注意的是,上述成本僅包括 DeepSeek-V3 的正式訓練成本,不包括與架構、算法或數據的前期研究及消融實驗相關的成本。

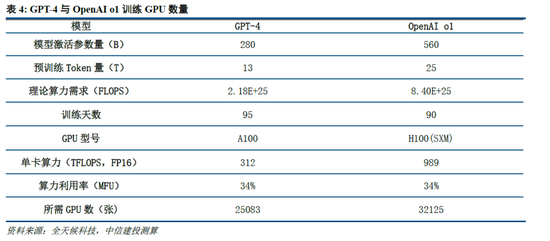
根據我們測算,GPT-4需要2.5萬張A100訓練95天(5700萬A100 GPU小時),OpenAI o1需要用3.2萬張H100訓練90天(6912萬H100 SXM GPU小時):1)GPT-4由16個111B的MoE模型構成,其中兩個用於向前傳播,另有55B被用做注意力機製的共享,則GPT-4的激活參數量約為280B,我們假定o1模型激活參數量是GPT-4的兩倍,達到560B;2)GPT-4的預訓練數據集token量為13B,我們假定o1模型接近其兩倍,達到25B;3)GPT-4的訓練時間約為90-100天,我們取中間值95天,並假定o1的訓練周期為90天;4)GPT-4的GPU利用率在32%到36%之間,我們取中間值34%,並假定o1 GPU利用率也為34%;5)根據OpenAI在Scaling Laws 論文中給出的經驗公式計算(C = rT ≈ 6*P*D,P為模型參數量,D為訓練集token大小,r為訓練集群硬件FLOPS總吞吐),則OpenAI o1預訓練需要用3.2萬張H100。

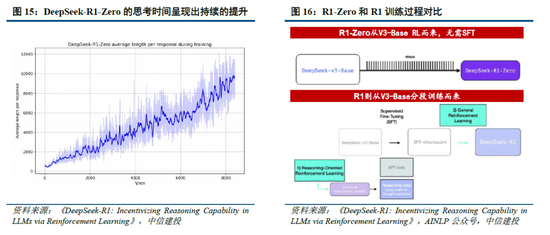
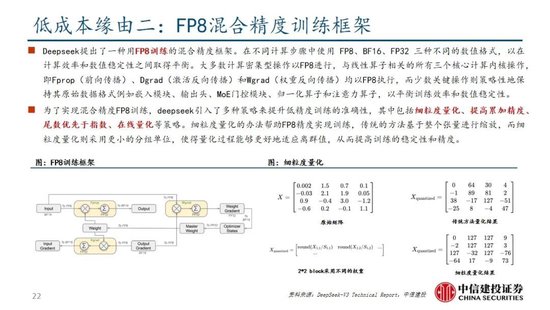
算法迭代、架構升級促進DeepSeek-V3模型訓練成本降低,符合產業趨勢。相較於GPT-4和o1模型,DeepSeek-R1的基礎模型DeepSeek-V3訓練成本明顯更低,結合V3技術報告和上述計算過程,我們認為成本優化主要緣於:1)V3模型通過DeepSeekMoE架構(3.1中將進一步說明),使用更細粒度專家模型,同時隔離部分共享專家,提高計算資源利用率,激活參數少(僅37B),算力消耗低;2)V3模型采用MLA算法(3.1中將進一步說明),通過低秩聯合壓縮注意力鍵值,減少推理時的鍵值(KV)緩存,降低計算量;3)Dual Pipe框架實現高效流水線並行,或顯著提高GPU利用率;4)DeepSeek提出了一種利用FP8數據格式進行訓練的細粒度混合精度框架,通過低精度訓練優化訓練效率。
二、技術不斷革新,大模型Scaling Law仍有效
2.1 第四問:DeepSeek-V3/R1技術革新有哪些?
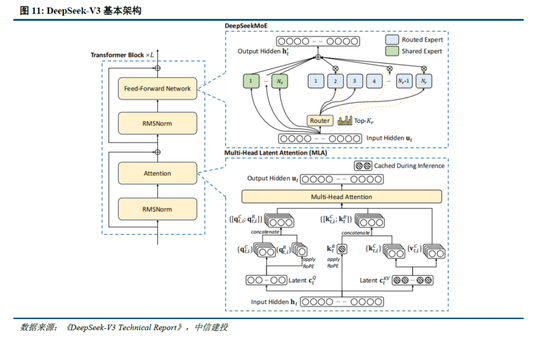
通過架構和基礎設施創新,DeepSeek-V3實現了高效訓練,奠定R1模型優化基礎。架構方麵,DeepSeek-V3延續了V2模型的MLA和DeepSeek MoE架構,同時進一步開創了無輔助損失的負載均衡策略,並設定了多token預測(MTP)訓練目標以增強性能:
多頭潛在注意力(MLA):LLM的核心機製是自注意力(Self-Attention),其要求模型在生成每個token時考慮之前所有詞的關係,則假設文本長度n時總體複雜度為〖O(n〗^3)=O(Σn^2);過去的研究提出了KV Cache方法,利用鍵值對(KV)存儲已計算的注意力信息,此時總體複雜度降低為O(n^2);而MLA則進一步通過投影的方式,將token的相異信息通過投影矩陣存儲,在幾乎不損失信息的情況下減少鍵值的緩存需求。
DeepSeekMoE:專家混合模型(MoE)是當前大模型技術中對前饋神經網絡(FNN)的一種替代方案。不同於FNN需要全部權重參與計算,MoE利用門控機製判斷輸入數據需要由哪些專家模型參與處理。相較於主流MoE模型,DeepSeekMoE使用更細粒度的專家,並隔離一些模型作為共享專家,進一步優化了激活參數。此外,為解決專家負載不平衡導致的路由崩潰和計算效率降低,DeepSeek提出無輔助損失負載均衡策略,為每個專家模型添加可動態調整的偏差項,確保訓練過程中專家負載平衡、提高模型性能。

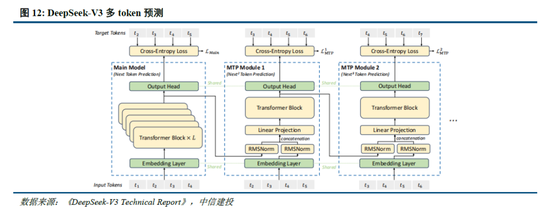
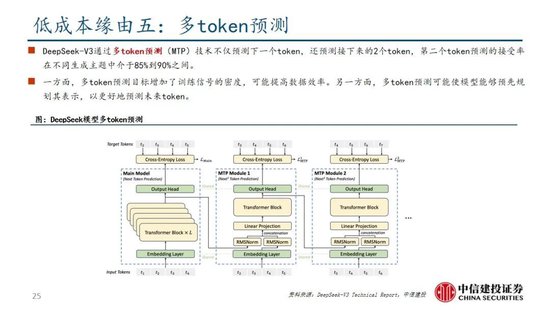
多token預測(MTP):主流大模型token-by-token生成序列,而每次token生成需要頻繁與訪存交互,從而因為訪存效率形成訓練或推理的瓶頸。MTP方法主要將單token的生成,轉變成多token的生成,提升訓練和推理的性能。DeepSeek主要對過往MTP算法進行了一定優化,順序預測額外token,並在每個預測深度保持完整的因果鏈。

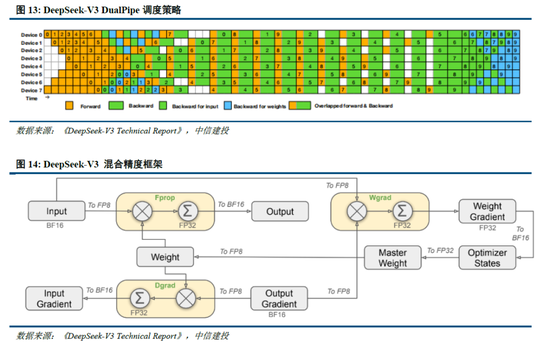
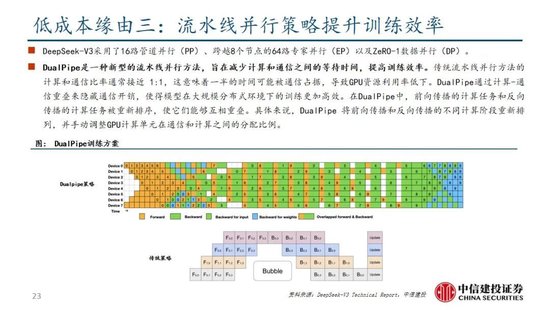
除了基礎架構,DeepSeek還在基礎設施方麵進行了一定優化。例如設計了一種創新的管道並行算法 DualPipe,在每一對前向和後向塊內重疊計算和通信,提高通信效率、加速了模型訓練;提出了一種用於 FP8 訓練的混合精度框架,其中大多數計算密集型操作在 FP8 精度下進行,而一些關鍵操作則戰略性地保持在原始數據格式以平衡訓練效率和數值穩定性;訓練過程中,采用英偉達 PTX(並行線程執行)匯編級編程替代標準 CUDA 方案,實現了硬件級深度優化,減少了計算冗餘,提高了推理速度。

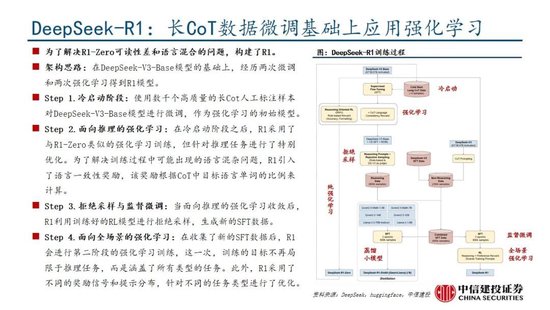
R1-Zero驗證純強化學習(RL)對推理能力的提升,R1則強調冷啟動和多階段訓練的平衡。R1-Zero的特別之處在於,其無需任何監督微調數據即可獲得強大的推理能力,反映了模型僅通過強化學習就能有效學習和泛化的能力。具體而言,R1-Zero模型在RL過程中延續了DeepSeek-V3組相對策略優化算法(GRPO),通過組內獎勵對比優化策略,而不需要額外的判別器,最終實現訓練集上的平均響應長度持續提升,自然地學會了通過更多的思考時間來解決推理任務;此外,R1-Zero訓練過程自然地湧現出“思考能力”,即模型自發學會了重新評估其初始回答,並為問題分配更多的思考時間,這種“反思”的特性能夠一定程度解決大模型幻覺問題(大模型逐token輸出,過去沒有機製去糾正已經輸出的錯誤,反而會繼續用錯誤掩蓋先前的問題,帶來幻覺問題)。
盡管R1-Zero模型展現了強大的推理能力,但仍麵臨可讀性差和語言混合等挑戰,R1模型則通過冷啟動和多階段訓練解決了上述問題。R1同樣從DeepSeek-V3-Base基礎模型出發,經過數千條優質長鏈思維(CoT)數據微調(SFT)作為冷啟動,使模型輸出更符合要求、可讀性更強;而後,針對微調後的模型采用與R1-Zero相同的大規模強化學習,並引入語言一致性獎勵,直至模型在推理任務上達到收斂;麵向推理的強化學習收斂後,利用生成的檢查點收集新的SFT數據,從而融入來自其他領域的數據,以增強模型在寫作、角色扮演和其他通用任務中的能力;最後,為了進一步使模型與人類偏好保持一致,實施次級RL階段,旨在提高模型的有用性和無害性、精煉其推理能力。通過冷啟動和多階段訓練,R1模型最終具備較強的推理性能,同時在可讀性上表現較好。

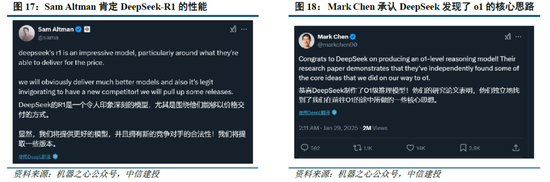
R1係列模型提供了RL Scaling Law的可行方向。實際上,在OpenAI推出o1模型時即發現了推理性能隨著訓練時間和測試時間計算而平穩提升的“RL Scaling law”,但業內尚未通過過程獎勵模型(PRM)和蒙特卡洛樹搜索(MCTS)等方法做出較好的效果,R1的技術報告更是提到PRM和MCTS存在難以規模化拓展、獎勵欺騙等問題。R1模型的技術報告提供了一種多階段訓練的方式,其中在第一階段RL過程中,研究人員可以通過擴大RL訓練集的方式提升模型性能,或為一種可以驗證的“RL Scaling law”方向;OpenAI首席研究官Mark Chen也承認,“DeepSeek的確獨立發現了一些o1的核心思路”。

蒸餾使小模型具備較強邏輯推理能力的思路或與OpenAI o1-mini不同。據張俊林分析,o1係列模型更可能是重新訓練的(OpenAI多次強調o1-mini邏輯推理能力強,但在世界知識方麵弱;如果其基於GPT係列模型而來,世界知識應該不會弱於GPT 4o-mini),而DeepSeek-R1則是在V3的基礎上通過強化學習訓練得到。因此,DeepSeek通過向更高效的小模型蒸餾DeepSeek-R1的輸出,顯著提升小模型推理能力,更可能走出了與OpenAI o1-mini不同的道路,從而實際上打破了之前“小模型邏輯推理能力難以通過蒸餾提升”的研究結論。
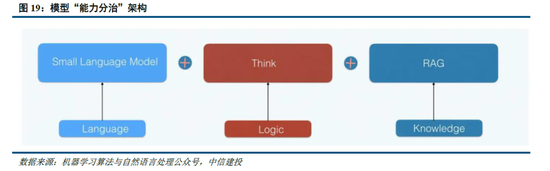
此時,小模型有望通過“能力分治”(DCA)的模式將語言、世界知識及邏輯推理三個能力解耦,即語言能力靠小模型自身、邏輯推理靠RL+蒸餾,世界知識靠外掛RAG,從而具備目前最強大模型的能力,對於中小型開發者而言,部署模型也將更加友好。

我們認為,DeepSeek-V3/R1係列模型的核心突破在於1)技術及架構升級顯著優化模型訓練成本,即工程優化了MoE模型架構,預計未來各廠商仍將圍繞MoE模型進行注意力頭的架構優化;2)組相對策略優化算法(GRPO)實質上僅依賴模型自身近些迭代,實現了“反思能力”;3)提供了一種具體可行的“RL Scaling law”方向,各廠商或將跟進並繼續探索其他方向;4)蒸餾使小模型具備較強邏輯推理能力,有望促進中小型開發者推出相關應用。

2.2 第五問:Janus係列模型技術革新有哪些?
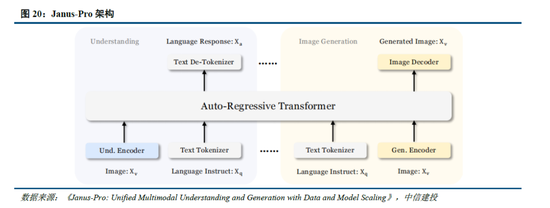
Janus係列模型緩解多模態理解和生成的衝突,提升模型能力表現。多模態理解與生成任務本身存在視覺編碼器需求的衝突,其中在理解任務中,視覺編碼器的目的是提取高層次的語義信息並進行表示;而生成任務則主要關注生成局部細節並在圖像中保持全局一致性,因此需要低維度編碼表示空間結構和紋理細節。Janus係列模型的核心技術在於實現多模態理解與生成的解耦,通過2 個獨立的視覺編碼路徑,緩解多模態理解和生成的衝突,從而提高模型的能力表現和可擴展性。
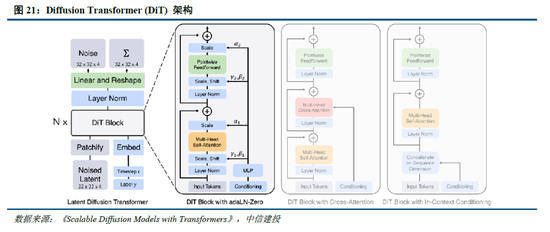
多模態生成模型架構尚無定論,自回歸和擴散模型持續發展。目前圖像生成模型主要包括以Transformer 為代表的自回歸生成、以 DDPM、LDM、DiT 為代表的擴散模型,以及 MaskGIT、MAR等掩碼自回歸圖像生成三類架構。自回歸架構通過算法逐個生成像素,DeepSeek的Janus係列模型為其中代表;掩碼自回歸則優化了單次像素生成數量和順序,提高了自回歸模型的速度和表現;擴散模型的代表包括Sora,其將圖像生成表示成噪聲圖像變化至目標圖像的過程,輸入輸出自始至終都是完整圖像。目前,自回歸和擴散模型均有前沿技術持續性突破,帶來模型能力的持續提升。

我們認為,多模態模型整體仍處於技術探索過程中,Janus係列核心在於提供了一種理解和生成解耦的架構,一定程度提升了模型表現,後續自回歸和DiT技術將進一步發展,帶來多模態模型性能的持續優化。
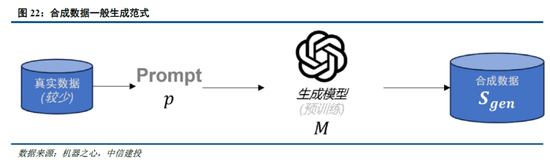
2.3 第六問:DeepSeek數據集的特點是什麽?
合成(生成)數據在大模型訓練過程中發揮著重要作用。在高質量訓練數據耗盡,以及互聯網中充斥大量噪聲數據的背景下,合成數據已成為大模型訓練過程中數據集的重要來源, 截至 2024 年 9 月,在 Hugging Face 平台上標注為 “合成” 的數據集已超過 1000 個。具體而言,合成數據主要由算法、模型生成,為大模型訓練提供更豐富且針對性強的信息,幫助拓展模型性能:
通用大模型:在通用大模型訓練中,合成數據主要用於豐富數據集,提升模型性能。以 DeepSeek-V3 的訓練為例,其在監督微調階段借助 DeepSeek-R1 模型生成樣本數據,經 RL 訓練後用拒絕采樣篩選高質量數據用於最終模型訓練,有效提升了模型的推理能力。
推理模型:在推理模型訓練中,合成數據主要用於優化訓練流程。例如,DeepSeek-R1在冷啟動階段利用R1-Zero生成+人工標注數據進行微調,並在監督微調階段通過V3模型收集了約60萬條與推理相關的訓練樣本,以及約20萬條與推理無關的訓練樣本。此外,R1向小模型蒸餾的過程實際上也是通過R1生成數據對小模型進行監督微調實現的。
多模態模型:多模態模型訓練中,合成數據能改善數據質量,顯著強化視覺生成能力。Janus - Pro 在預訓練階段相較於 Janus 引入約 7200 萬個合成美學數據樣本,使真實數據與合成數據比例達到 1:1,從而加速了模型收斂速度,提升圖像生成質量。而Kimi-1.5作為以強化學習方式訓練的多模態大模型,分別在預訓練階段通過合成數據強化了推理和基於知識任務的解答能力,在多模態訓練階段合成了圖像文本交錯數據。

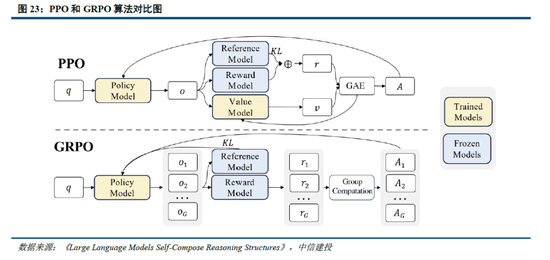
GRPO 算法在一定程度上使模型擺脫人類經驗的束縛。如 2.1 所述,R1 - Zero 模型在 RL 過程中延續了 DeepSeek - V3 組的相對策略優化算法(GRPO)。該算法通過組內獎勵對比優化策略,無需額外的判別器,最終實現了訓練集上平均響應長度的持續提升,使模型自然地學會通過更多思考時間來解決推理任務。實際上,GRPO 對於 RL 數據集的處理同樣具有重要意義。具體而言,PPO 算法需要依賴價值模型估計狀態價值,以幫助計算優勢函數;而 GRPO 算法隻對輸出的語言內容進行相對優勢計算,不需要設計價值模型。價值模型的設定本身就包含了人類偏好,這種偏好通過人類經驗限定了數據集的價值。而 GRPO 算法本質上可看作模型生成內容的自我博弈,它能讓模型擺脫人類經驗的束縛,通過提升思考深度不斷拓展性能,最終甚至可能超越人類水平。

我們認為,DeepSeek-V3/R1/Janus等模型對於合成數據的應用符合大模型研究趨勢,而GRPO 算法則進一步使模型在RL過程中擺脫了人類經驗的限製,從而能夠最大程度挖掘數據集的價值,向模型超越人類,最終實現AGI的道路進發。
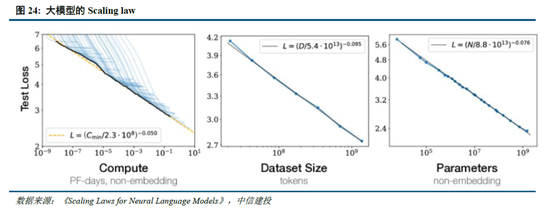
2.3 第七問:Scaling Law到底是否有效?
訓練側Scaling law推動模型能力持續提升,但仍麵臨技術、算力、數據的製約。早在2020年,OpenAI即在論文中提出了“Scaling law”,其內涵在於大模型的最終性能主要與計算量、模型參數量和訓練數據量三者的大小相關,而與模型的具體結構(層數/深度/寬度)基本無關。在“Scaling law”的思路下,業內追求在訓練側用更多的高質量數據,訓練更大參數規模的模型,尤其在MoE架構並行計算的加持下,大模型參數甚至能夠提升至萬億以上,極大程度提高了模型的效果。
然而,受到技術、算力、數據的製約,訓練側“Scaling law”正麵臨瓶頸:1)更高參數規模的模型訓練比較複雜:當參數規模提升到萬億規模,模型進一步調整的技術方式仍待突破;2)算力規模一定程度製約了模型發展:英偉達 H100目前可以做到單一集群 3.2 萬張卡充分互聯,每2小時會出錯一次(Founder Park訪談拾象科技 CEO 李廣密)。一旦算力集群增加到10萬卡,可能每20-30分鍾即會出錯一次,對數據中心的運維能力要求較高,否則會導致算力利用率明顯下降。此時需要性能更強的算力卡出現。3)高質量數據缺失:早有消息稱大模型訓練已經耗盡了高質量數據,因此如果隻是簡單提升訓練集規模,往往重複的數據占據了主要部分,從而對模型能力的提升有限。而數據合成的技術仍未能突破,同樣一定程度上製約了模型的發展。

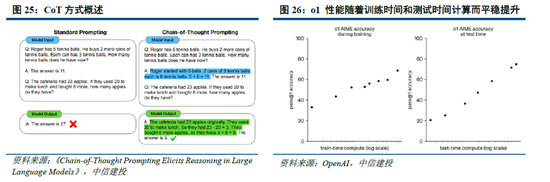
思維鏈等方式打開推理側大模型能力提升空間。當訓練側“Scaling law”進度相對放緩,OpenAI於2024年9月發布了係列新模型o1,其利用強化學習技術,通過提高推理側的思考時間,大幅優化了模型表現;還能夠在訓練過程中生成高質量數據,解決天然數據缺失的問題。以思維鏈技術為例,其類比人類思考過程,使大模型在推理過程中把複雜問題拆解成若幹簡單步驟,從用戶提出的問題出發,逐步生成正確答案。OpenAI o1模型性能隨著訓練時間和測試時間計算而平穩提升,後訓練及推理階段思考深度(時間)或將成為 新的“Scaling law”;相較於OpenAI未開源推理算法,DeepSeek-R1係列模型提供了RL Scaling Law的可行方向,有望促進各廠商跟進並繼續探索其他推理側拓展方向。

Scaling law三條路徑齊頭並進,助力模型性能持續提升。正如英偉達CEO黃仁勳在CES 2025上的主題發言提到的,o1模型推出後,大模型Scaling law已經實際上分為了三個路徑:
Pre-Training Scaling:對應OpenAI 2020年提出的結論,訓練數據規模越大、模型規模越大、計算資源投入越多,AI模型的性能就會相應提升。盡管Pre-Training Scaling目前受技術、算力、數據影響遭遇瓶頸,但更強大的基礎模型仍然是各廠商追求的主要方向,DeepSeek-R1的技術報告同樣提出,“更大基礎模型發現的推理模式對於提升推理能力至關重要”。未來隨著MoE架構、模型Infra等方麵的優化,Pre-Training Scaling有望持續發展。
Post-Training Scaling:包括強化學習和人類反饋等技術,通過輸入大量優質的提示,優化模型性能表現。實際上,受限於人類工作效率,原有的人類反饋強化學習(RLHF)存在難以規模化擴張的問題(例如人工標注數據效率較低、不同標注者標準不一致等),而DeepSeek-R1純RL的技術方案實際上打破了這種限製,為各廠商提供了Post-Training Scaling的可行方案。
Test-Time Scaling:強調重新調配資源,即在推理階段考慮投入多少算力,並利用思維鏈將問題分解成若幹個小步驟逐一解決。通過在模型推理階段更加深入的思考,模型將具備更強勁的性能。

我們認為,Scaling Law仍有效,同時RL技術的不斷迭代為模型能力的規模化擴張帶來了新的方向。特別是DeepSeek通過架構和技術創新,提出了純RL和分階段的模型訓練方法,並實現了較好的性能表現。預計各廠商將陸續跟進DeepSeek的算法方向,並不斷對架構進行調整,以探索出更為理想的模型優化方式。
三、DeepSeek-R1促進AI平權,產業鏈享受發展紅利
3.1 第八問:R1是否意味著AI平權已經實現?
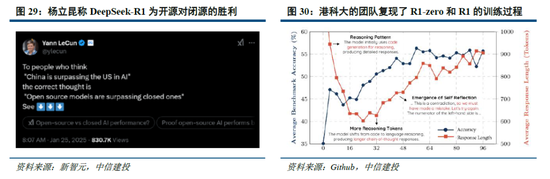
DeepSeek-R1開源引發全球複現熱潮,小模型+RL實現“反思”湧現。在美國對中國實施 AI 芯片封鎖的背景下,DeepSeek以極低的成本成功訓練出躋身全球第一梯隊的推理模型 R1。同時,DeepSeek 完全開源了模型權重,所遵循的 MIT License 開源協議極為寬鬆,允許其他開發者將模型用於商業用途並進行模型蒸餾,被Facebook首席人工智能科學家楊立昆譽為“開源模型對閉源模型的勝利”。
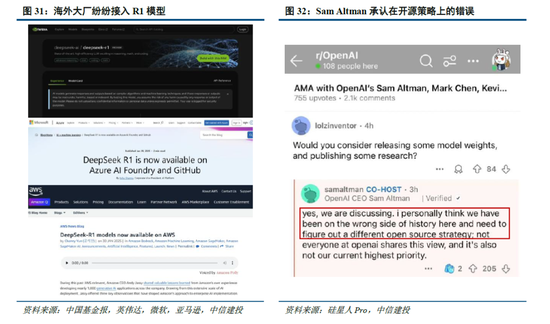
R1發布以來,全球前沿團隊積極複現,目前已取得較好成效。其中,UC伯克利的團隊在CountDown遊戲中複現了DeepSeek R1-Zero,以不到30美金的成本通過強化學習,使3B的基礎語言模型完成自我驗證和搜索;港科大的團隊隻用了8K個樣本,就在7B模型上複刻出了DeepSeek-R1-Zero和DeepSeek-R1的訓練,使模型在複雜的數學推理上取得強勁的結果;甚至全球最大開源平台HuggingFace團隊,也在1月26日官宣開始複刻DeepSeek-R1的所有pipeline,並將在複刻完成後,開源所有的訓練數據和腳本。

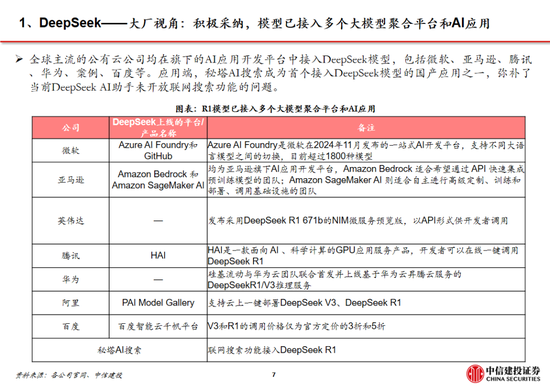
全球大廠接連接入R1,DeepSeek衝擊下OpenAI戰略方向或將轉向。盡管美國質疑DeepSeek在安全性、隱私方麵的問題,但英偉達、英特爾、亞馬遜、微軟、AMD等海外巨頭仍紛紛在自家產品中接入了DeepSeek;國內矽基流動和華為雲同樣聯合首發並上線了基於華為雲昇騰雲服務的DeepSeek R1/V3推理服務。受DeepSeek全球熱度衝擊,Sam Altman承認在開源策略上“站在了曆史錯誤的一邊”,並表示正在討論開源部分模型。此外,OpenAI於2月1日緊急更新了o3-mini係列,即使是免費用戶也可以通過選擇“Search+Reason”來使用體驗o3-mini的搜索功能。然而,o3-mini模型當前的定價為每百萬輸入 tokens 0.55美元(緩存命中)/ 1.1美元(緩存未命中),每百萬輸出 tokens 4.4美元,遠高於R1模型。

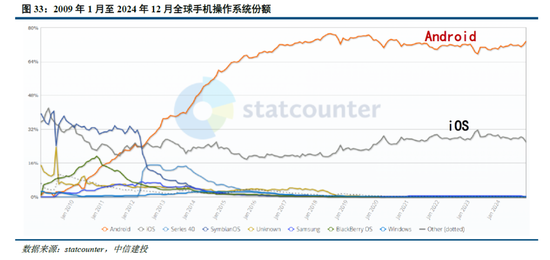
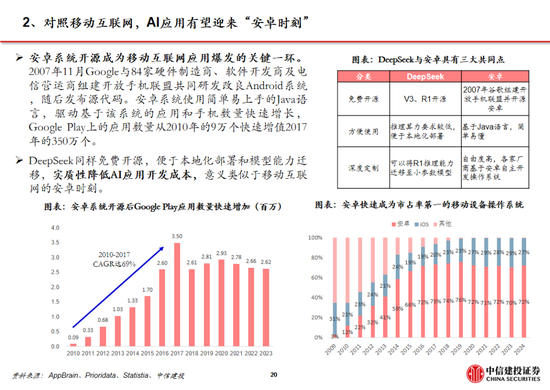
參考安卓及iOS份額變化,開源生態有望為AI產業注入活力。在智能手機操作係統領域,安卓的開源與 iOS的封閉帶來了截然不同的生態模式:
安卓:Android公司成立於2003年,2005年被Google收購,並在2007年正式推出了Android操作係統。生態上,安卓係統開源開放,允許眾多手機廠商基於其底層架構進行定製化開發,使其市場份額從2008年的2.8%提升到2011年的48%,但同時也帶來了專利訴訟、軟件盜版和係統安全等一係列問題;2011年,Google 推出 Android 4,從此安卓設備逐步正規化、標準化,直至2024年12月,安卓操作係統市場份額已經達到73.49%。
iOS:同樣在安卓係統正式發布的2007年,蘋果發布了搭載iOS係統的第一代iPhone,開啟了智能手機的新時代。相較於安卓的開放,蘋果iOS係統采用封閉式生態,嚴格把控軟件審核環節,一定程度限製了係統的靈活性,但為用戶提供了一致且高質量的使用體驗。從市場份額看,近年來iOS係統的市占率相對穩定,2024年12月市場份額為26.04%,低於2009年1月iOS的市場份額35.56%。
AI產業:類比手機操作係統領域,當前AI 產業同樣麵臨開源和閉源之爭。參考安卓係統發展曆程,開源模式能夠吸引全球範圍的開發者參與AI技術創新,後來者能夠基於已有成果快速進行應用開發與產品迭代,從而推動 AI 應用的快速落地,推動AI產業加速發展。

我們認為,DeepSeek-R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權。實際上,過去OpenAI的領先更多基於先發優勢,而當開源模型的性能實現對閉源模型的追趕,全球的團隊的研發能力能夠使開源模型的性能始終位於前列。近期各研究團隊對R1模型的積極複現更是側麵驗證了開源模式的優勢。此外,DeepSeek-R1使小模型具備推理能力成為可能,更低的成本將更有利於開發者探索AI的實際落地,帶來更有價值的產品。
3.2 第九問:DeepSeek出圈對產業的影響有幾何?
DeepSeek以其低成本、高性能全麵影響AI產業鏈。AI產業鏈大致可分為基礎層(算力、數據、技術等)、模型層(通用/行業大模型、開發平台)和應用層(通用/垂域應用、Agent等)。盡管創始人梁文鋒稱DeepSeek技術突破隻是“美國每天發生的大量創新裏非常普通的一個”,但其低成本、高性能,以及為小模型帶來強大推理能力的蒸餾方式,仍對AI產業鏈產生了衝擊:

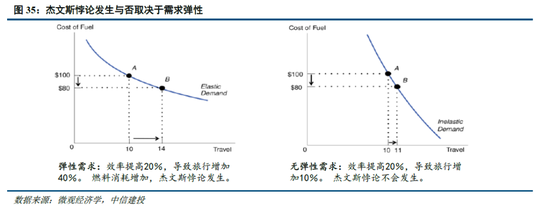
算力:DeepSeek的爆火使得“傑文斯悖論”這一經濟學名詞受到關注,它是指“燃料效率的提高往往會增加燃料使用”。如果將該理論拓展到算力領域,模型對算力應用效率的提升反而會帶來算力需求的增長。實際上,“傑文斯悖論”反映了簡單的經濟學原理——當需求價格彈性係數大於1,價格下降則會帶來銷售收入增加。因此,DeepSeek影響下算力需求是否增加的關鍵在於算力的價格彈性,而這又受到算力用途的影響(一般來說,商品用途多,需求彈性就越大)。
算力作為新一輪科技革命的底層基礎,將會應用於千行百業,DeepSeek-R1使小模型能通過蒸餾具備較強邏輯推理能力,更進一步加速了下遊應用的產生,則算力的價格彈性更可能大於1,符合“傑文斯悖論”,從而持續保持旺盛的需求。此外,梁文鋒在訪談中提到高端芯片禁運或將成為卡點,同樣反應了算力芯片自主可控的重要性。

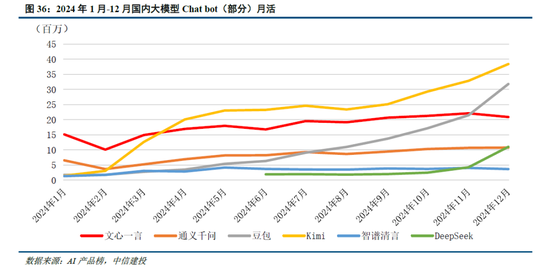
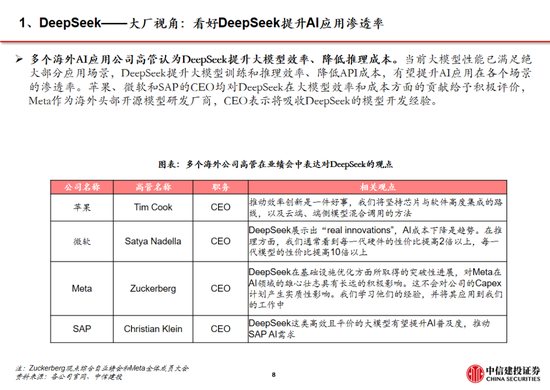
模型:DeepSeek-R1模型的突破實際上反映了中美在前沿大模型差距的縮小。以發布於2024年3月的GPT-4為例,2024年1月發布的智譜GLM-4才在部分benchmark上達到了其90%-100%的水平,模型差距在10個月以上;而2025年1月發布的R1已經接近OpenAI 2024年9月發布的o1模型,模型差距縮短到4個月左右。而大模型本身及其對應的Chat bot產品,用戶切換成本低,存在“贏者通吃”的現象,例如kimi 在2024年3月實現上下文無損輸入長度提升至200萬字,爆火出圈帶來流量的大幅上漲;2024年12月字節火山引擎熱度攀升,以及DeepSeek-V3的發布同樣帶來了流量的快速提升。在此背景下,預計大廠將跟進DeepSeek模型層的研發,技術開源亦將促進大廠持續投入,形成正反饋。此外,DeepSeek通過純RL算法、架構優化等方式實現了模型性能的提升,或將促進各廠商在相關領域進行更多的探索。

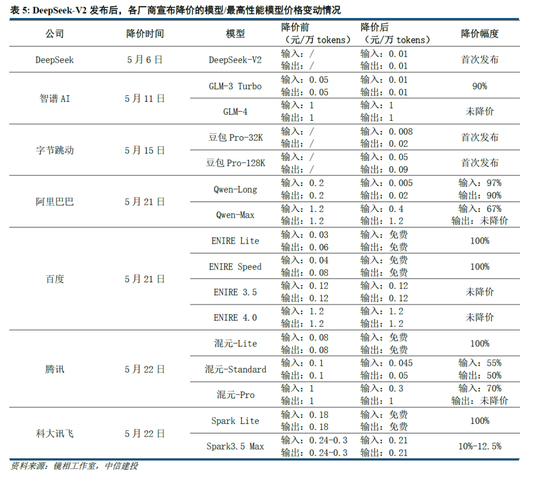
應用:DeepSeek-V3/R1作為通用/推理方麵的基礎模型,性能升級及在各類 Benchmark 跑分中的提高,本身就為應用落地帶來了更大的可能性。然而,對於開發者而言,更關鍵的點在於模型能夠和應用適配調優,提供穩定性的API服務,以及性價比更高的tokens成本。參考2024年5月DeepSeek-V2發布後帶來的大模型價格戰,即使模型成本更高,字節、阿裏等大廠亦按照燒錢補貼的邏輯大幅降價,本質上是因為開發者價格敏感,大廠願意虧錢搶占市場份額,培育開發者使用習慣。
考慮到DeepSeek-R1開發和調用成本本身較低,還通過蒸餾的方式帶來了小模型推理能力的提升,則應用開發者能夠以更低的成本部署模型或調用API,並保持相對優秀的性能。當應用開發門檻降低,預計會出現更多產品探索方向,直至出現具有突破性的 “killer”應用。同時,DeepSeek-R1的低價,同樣有望帶來推理模型新一輪的價格戰(o3-mini的價格本身已經驗證了這一觀點),為開發者帶來更多性價比之選。最後,當DeepSeek模型的能力達到全球第一梯隊後,其作為國內廠商能為國內應用開發者提供更穩定的服務(調用GPT API可能會受到各種限製),亦將促進各類應用產生。

數據:DeepSeek 係列模型的訓練過程仍凸顯了高質量數據的重要性。例如V3模型訓練時使用了14.8 萬億涵蓋多種領域和語言的token;R1通過精心篩選和處理的冷啟動數據提升了模型性能和可讀性;Janus-Pro 在訓練時同樣較前代模型增加約 9000 萬用於多模態理解的樣本和約 7200 萬用於視覺生成的合成美學數據。結合RL範式的可能性,預計高質量數據仍將在模型訓練中具有重要意義。
四、投資建議
4.1 第十問:DeepSeek將帶來哪些投資機會?
算力:算力作為新一輪科技革命的底層基礎,將持續受益於千行百業的應用需求。疊加 DeepSeek - R1 為推理範式帶來泛化的可能性,預計各廠商技術探索下算力產業鏈持續高景氣。此外,中美AI競爭加劇,高端算力芯片禁售下自主可控重要性進一步凸顯。建議關注以國產算力和AI推理需求為核心的算力環節,尤其是IDC、服務器、國產芯片等算力配套產業。
應用:DeepSeek-R1有望引發新一輪大模型API降價,小模型通過蒸餾具備強勁推理能力,這也將促使開發者探索更多應用落地的可能性。AI應用作為新一代生產力工具,看多C端軟件的持續發展,B端應用軟件商業化進展更快。建議關注B端Agent,其中OA+ERP作為核心入口,AI結合更易,有望率先商業化,其次關注用戶量多、生態好且可雲化的軟件公司等。
端側:小模型能力提升同樣促進了端側模型部署,我們看好AI終端作為新一代計算平台爆發可能。首先,我們認為AI+教育作為高頻應用場景有望率先落地,特別教育部人工智能賦能教育行動陸續推進,有望帶動AI學習機、AI教育大屏等需求增加,推薦、等;其次,我們認為AI眼鏡、AIPC、等新終端的出貨量有望隨著模型升級後使用範圍的增加而增加,因此建議關注以AI眼鏡、PC、機器人為代表的終端供應商或內部核心軟件供應商。
數據 :高質量數據仍然是大模型訓練中不可或缺的一環,B端 Agent落地亦需要行業know-how進行微調。建議關注向量數據庫相關公司、數據處理類企業,以及具備行業側專業數據的廠商。
風險提示:(1)AI產業商業化落地不及預期:目前各環節AI 產品的商業化模式尚處於探索階段,如果各環節產品的推進節奏不及預期,或對相關企業業績造成不利影響;(2)市場競爭風險:海外 AI 廠商憑借先發優勢,以及較強的技術積累,在競爭中處於優勢地位,如果國內 AI 廠商技術迭代不及預期,經營狀況或將受到影響;同時,目前國內已有眾多企業投入AI產品研發,後續可能存在同質化競爭風險,進而影響相關企業的收入;(3)政策風險:AI技術的發展直接受各國政策和監管影響。隨著AI在各個領域的滲透,政府可能會進一步出台相應的監管政策以規範其發展。如果企業未能及時適應和遵守相關政策,可能麵臨相應處罰,甚至被迫調整業務策略。此外,政策的不確定性也可能導致企業戰略規劃和投資決策的錯誤,增加運營的不確定性;(4)地緣政治風險:在全球地緣政治環境的波動下,尤其美國對中國的出口限製或將直接影響國內企業算力芯片的獲取,進而影響其產品研發和市場競爭力。同時,地緣政治風險也可能導致 AI 產品開拓海外市場麵臨障礙,影響相關企業的營收情況。
報告來源

證券研究報告名稱:《DeepSeek核心十問十答》
對外發布時間:2025年2月4日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
應瑛 SAC 編號:S1440521100010
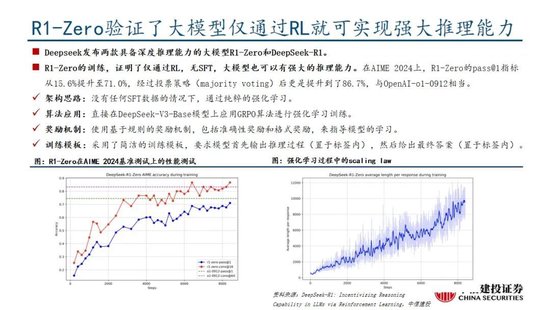
02 DeepSeek R1深度解析及算力影響幾何
Deepseek發布深度推理能力模型,性能和成本方麵表現出色。Deepseek發布兩款具備深度推理能力的大模型R1-Zero和DeepSeek-R1。R1-Zero采用純粹的強化學習訓練,模型效果逼近OpenAI o1模型,證明了大語言模型僅通過RL,無SFT,大模型也可以有強大的推理能力。但是R1-Zero也存在可讀性差和語言混合的問題,在進一步的優化過程中,DeepSeek-V3-Base經曆兩次微調和兩次強化學習得到R1模型,主要包括冷啟動階段、麵向推理的強化學習、拒絕采樣與監督微調、麵向全場景的強化學習四個階段,R1在推理任務上表現出色,特別是在AIME 2024、MATH-500和Codeforces等任務上,取得了與OpenAI-o1-1217相媲美甚至超越的成績。
國產模型邁向深度推理,策略創新百花齊放。在Deepseek R1-Zero模型中,采用的強化學習策略是GRPO策略,取消價值網絡,采用分組相對獎勵,專門優化數學推理任務,減少計算資源消耗;KIMI 1.5采用Partial rollout的強化學習策略,同時采用模型合並、最短拒絕采樣、DPO 和long2short RL策略實現短鏈推理;Qwen2.5擴大監督微調數據範圍以及兩階段強化學習,增強模型處理能力。
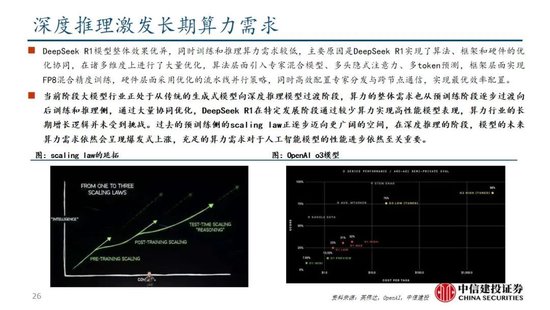
DeepSeek R1通過較少算力實現高性能模型表現,主要原因是DeepSeek R1實現算法、框架和硬件的優化協同。DeepSeek R1在諸多維度上進行了大量優化,算法層麵引入專家混合模型、多頭隱式注意力、多token預測,框架層麵實現FP8混合精度訓練,硬件層麵采用優化的流水線並行策略,同時高效配置專家分發與跨節點通信,實現最優效率配置。當前階段大模型行業正處於從傳統的生成式模型向深度推理模型過渡階段,算力的整體需求也從預訓練階段逐步過渡向後訓練和推理側,通過大量協同優化,DeepSeek R1在特定發展階段通過較少算力實現高性能模型表現,算力行業的長期增長邏輯並未受到挑戰。過去的預訓練側的scaling law正逐步邁向更廣闊的空間,在深度推理的階段,模型的未來算力需求依然會呈現爆發式上漲,充足的算力需求對於人工智能模型的性能進步依然至關重要。






























風險提示:
大模型技術發展不及預期:大模型屬於先進AI算法,若後續大模型算法更新迭代效果不及預期,則會影響大模型演進及拓展,進而會影響其商業化落地等;
商業化落地不及預期:大模型的商業落地模式在業界中普遍處於探索階段,用戶對於大模型的接受程度和商業化變現能力可能不及預期;
算力基礎設施支持不及預期:美國製裁技企業,對中國形成芯片、算力的封鎖,大語言模型訓練過程中需要大量算力資源,需要關注中美關係帶來的算力的壓力;
政策監管力度不及預期:大語言模型帶來新的網絡生態商業,尚屬於前期成長階段,政策監管難度加大,相關法律法規尚不完善,政策監管力度可能不及預期;
數據數量與數據質量不及預期:大型語言模型需要大量的高質量數據進行訓練,若數據數量和質量存在短板,則會影響大語言模型效果。
報告來源
證券研究報告名稱:《DeepSeek R1深度解析及算力影響幾何》
對外發布時間:2025年2月3日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
於芳博 SAC 編號:S1440522030001
龐佳軍 SAC 編號:S1440524110001
辛俠平 SAC編號:S1440524070006
研究助理:孟龍飛
03 重點推薦端側AI產業
DeepSeek在保持模型優異性能指標的同時大幅降低訓練和推理成本。2025年1月20日,DeepSeek-R1發布,以 DeepSeek-V3 模型為基礎,通過結合大規模強化學習、專家模型架構、FP8混合精度等技術手段降低訓練成本,同時具備深度思考能力,在數學、代碼、自然語言推理等多個任務上性能比肩 OpenAI O-1217 模型。DeepSeek-R1發布後,在保持較為優異的性能指標基礎上,市場對於其在訓練和推理端的低成本尤為重視。DeepSeek-V3 使用 2048 塊 H800 GPU 完成了 6710 億參數的訓練,訓練成本為 557.6 萬美元,DeepSeek-R1模型的每百萬輸出 tokens 為 16 元,均顯著低於同等水平的模型成本。
利用DeepSeek模型生成的數據樣本實現小參數量的模型蒸餾,提升模型性能。DeepSeek R1 生成 80 萬條高質量推理數據樣本,使用這些推理數據對較小的基礎模型進行監督微調(SFT),將 DeepSeek R1的知識和推理能力進行遷移。DeepSeek 團隊開源了多個基於不同規模的 Qwen 和 Llama 架構的蒸餾模型,如 DeepSeek - R1 - Distill - Qwen - 1.5B、DeepSeek - R1 - Distill - Llama - 8B、DeepSeek - R1 - Distill - Llama - 70B 等。
高性能、輕量化、低成本的模型能力將顯著推動端側AI產業發展。端側硬件設備是將大模型能力進行實物化輸出落地的關鍵環節,近日OpenAI 的 CEO Sam Altman 在接受媒體采訪時也透露 OpenAI 將開發可替代手機的生成式 AI 專用終端。國內物聯網模組廠商在端側AI領域具備先發優勢,並積極進行產業布局,如正加速開發DeepSeek-R1模型在端側落地應用及端雲結合整體方案,2025年將推出單顆模組算力達到100Tops的高階AI硬件,遠期規劃AI模組算力超過200Tops。
風險提示:國際環境變化對供應鏈的安全和穩定產生影響,對相關公司向海外拓展的進度產生影響;人工智能行業發展不及預期,影響雲計算產業鏈相關公司的需求;市場競爭加劇,導致毛利率快速下滑;匯率波動影響外向型企業的匯兌收益與毛利率,包括ICT設備、光模塊/光器件板塊的企業;數字經濟和數字中國建設發展不及預期;電信運營商的雲計算業務發展不及預期;運營商資本開支不及預期;雲廠商資本開支不及預期;通信模組、智能控製器行業需求不及預期。
報告來源
證券研究報告名稱:《重點推薦端側AI產業》
對外發布時間:2025年2月5日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
閻貴成 SAC 編號:S1440518040002
SFC 編號:BNS315
劉永旭 SAC 編號:S1440520070014
SFC 編號:BVF090
武超則 SAC 編號:S1440513090003
SFC 編號:BEM208
研究助理:朱源哲
04 DeepSeek激活創新競爭,AI應用迎來“安卓時刻”
應用開發迎來“安卓時刻”
回顧安卓與iOS應用的發展,我們率先提出不應隻關注大模型本身的用戶數及活躍度,更應該關注開發者,尤其是中小開發者的數量。據GitHub,在Llama比DeepSeek開源時間早1年半的情況下,目前DeepSeek R1在GitHub上的開發者點讚數量已經達到約5.7萬,接近Llama。根據GitHub、Hugging Face社區上的開發者實測,經過R1微調的80億參數小模型可以在個人筆記本中運行,本地化部署門檻顯著下降,應用的開發將迎來百花齊放。
有用戶有產品能力的公司,仍將“贏在起跑線”
雖然春節期間Deepseek的關注度趕超字節豆包,但我們認為以字節跳動為代表的中國頭部互聯網公司,手握高粘性+大DAU產品,疊加強產品能力。在第二階段的應用、場景等領域,用戶數+產品力+商業變現能力,仍然將幫助他們在接下來的競爭中搶占先機。
目前豆包全球累計下載量(約9000萬)仍然明顯高於Deepseek(約2000萬),而其他擁有用戶基礎和產品能力的公司,也有機會迎頭趕上。
























風險提示:宏觀經濟風險,版權保護力度不及預期,知識產權未劃分明確的風險,與IP或明星合作中斷的風險,大眾審美取向發生轉變的風險,競爭加劇的風險,用戶付費意願低的風險,消費習慣難以改變的風險,關聯公司公司治理風險,內容上線表現不及預期的風險,生成式AI技術發展不及預期的風險,產品研發難度大的風險,產品上線延期的風險,營銷買量成本上升風險,人才流失的風險,人力成本上升的風險,政策監管的風險,商業化能力不及預期的風險。
報告來源
證券研究報告名稱:《DeepSeek激活創新競爭,AI應用迎來“安卓時刻”》
對外發布時間:2025年2月4日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
楊艾莉 SAC 編號:S1440519060002
SFC 編號:BQI330
楊曉瑋 SAC 編號:S1440523110001
05 DeepSeek本地部署與全球資產配置組合跟蹤
Deepseek介紹:DeepSeek,成立於2023年,是幻方量化的子公司,位於杭州的人工智能公司。它於2024年末推出DeepSeek-V3模型(671B參數),性能超越多種開源模型,並接近頂尖閉源模型。2025年1月,DeepSeek發布R1係列模型(660B參數),在多項任務上表現優異,同時推出了幾個小模型對標OpenAI的產品。DeepSeek通過其創新技術顯著提高了生成速度,並提供了具有競爭力的API服務定價。
Deepseek本地部署方法:Ollama是一個開源工具,用於在個人設備上高效運行大型語言模型(LLMs),無需依賴雲端。DeepSeek-R1模型可通過Ollama實現本地部署:首先,從Ollama官網下載適合係統的Windows版本並安裝,完成後係統托盤會出現Ollama圖標。其次,訪問“Models”頁麵選擇DeepSeek-R1,並根據顯卡配置(如4090顯卡24G顯存)選擇32B版本,複製對應的運行指令。然後,在命令行窗口中執行該指令以下載和運行模型(32B版本約19GB)。為提升用戶體驗,可采用Docker+Open WebUI構建圖文交互界麵,甚至將DeepSeek-R1 32B集成到微信中作為智能體使用,享受其快速響應和深度思考功能。
對AI領域投資的思考:通過DeepSeek官網與DeepSeek-V3對話,可以了解部署各版本模型對硬件的要求。普通筆記本和台式機僅配備CPU,僅能勉強運行DeepSeek-R1-1.5B和7B,但響應速度慢,缺乏實用性。英偉達RTX 4090可較快運行DeepSeek-R1-32B,但在處理70B版本時表現不佳。中小模型如1.5B、7B和14B適合簡單的微信交流場景,但無法解決複雜問題;32B模型具備深度思考能力,適用於服務客戶的微信交流。671B完整版及70B模型需要企業級顯卡如A100或" target="_blank">中信建投:DeepSeek產業鏈投資機遇
來源:證券研究
中國DeepSeek爆火全球,為AI行業的發展注入了嶄新的活力,全麵引領AI浪潮。
近期DeepSeek多款模型上線並完全開源,其中R1在推理任務上基本實現於o1相當的性能,Janus-Pro 在多模態理解和生成方麵表現較好。受春節信息傳播下沉促進,DeepSeek出圈並成為全球增速最快的 AI 原生應用,日活躍用戶數在2月1日突破3000萬大關。此外,DeepSeek通過算法迭代、架構升級,使通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下。
中信建投證券計算機、人工智能、通信、傳媒、策略研究團隊推出【DeepSeek產業鏈投資機遇】:
01 DeepSeek核心十問十答
DeepSeek-R1模型發布,具有高性能、低算力需求的特性,帶動小模型推理能力的提升,引發全球開發者及用戶關注。R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權,同時純強化學習對推理能力的提升帶來RL範式泛化可能,預計後續基模的持續迭代,有望推動AI全產業鏈持續保持高景氣和高關注度,關注算力、應用、端側、數據等核心投資機會。
DeepSeek模型密集更新,高性能+低成本促進用戶數高增
近期DeepSeek多款模型上線並完全開源,其中R1在推理任務上基本實現於o1相當的性能,Janus-Pro 在多模態理解和生成方麵表現較好。受春節信息傳播下沉促進,DeepSeek出圈並成為全球增速最快的 AI 原生應用,第18天達到1500萬日活。此外,DeepSeek通過算法迭代、架構升級,使通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下。
技術不斷革新,大模型Scaling Law仍有效
DeepSeek通過多頭潛在注意力、MoE、多token預測等架構和基礎設施創新實現了高效訓練,並在R1-Zero模型驗證了純強化學習對推理能力的提升。盡管Pre-Training Scaling麵臨技術、算力、數據的製約,但強化學習帶來了規模化擴張新方向,預計各廠商將陸續跟進,持續優化模型架構。
DeepSeek-R1促進AI平權,產業鏈享受發展紅利
R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權。同時,R1使小模型具備推理能力成為可能,更低的成本將更有利於開發者探索AI的實際落地。
一、DeepSeek模型密集更新,高性能+低成本促進用戶數高增
1.1 第一問:DeepSeek的用戶量趨勢?
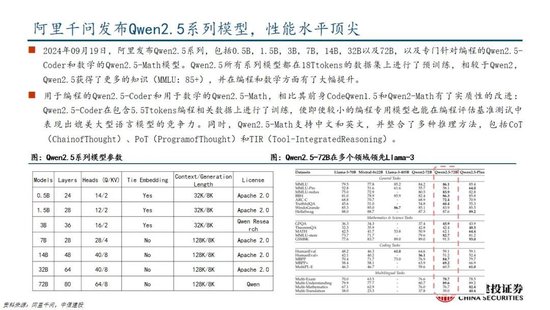
DeepSeek堅定開源路線,密集更新MoE、推理、多模態模型。近期,DeepSeek連續發布並開源多個大模型,其低成本、高性能的特性迅速引發全球用戶的關注。其中,2024年12月26日發布的DeepSeek-V3為671B參數的自研 MoE 模型,運行時僅需激活37B,在 14.8T token 的數據上進行了預訓練;2025年1月20日發布的DeepSeek-R1為660B的高性能推理模型,對用戶開放思維鏈輸出,允許用戶通過蒸餾技術借助 R1 訓練其他模型;2025年1月27日,DeepSeek在Hugging Face平台上傳了視覺模型 Janus-Pro和多模態理解模型JanusFlow -1.3B,進一步在圖像領域發力。

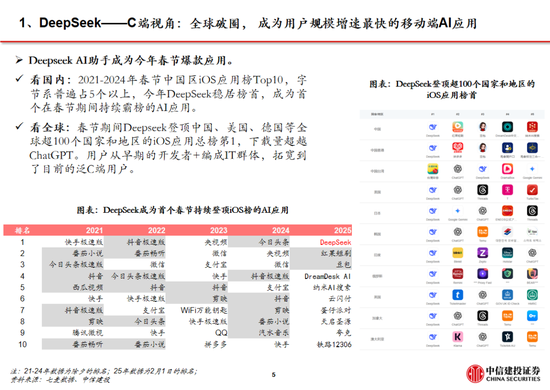
DeepSeek Web端與APP端訪問量持續增長,春節信息傳播下沉加速產品關注度裂變。Web端,2024年10月至2024年12月DeepSeek訪問量分別為245/422/1101萬,其中11月和12月分別同比增長72.24%/160.90%,12月受全模型V3促進訪問量大幅增長;APP端,DeepSeek 2025年1月10日(官方公眾號1月15日正式發文)在iOS/Android上線官方APP,而後受益於1月20日發布R1模型的高性能、低成本,疊加春節期間信息傳播下沉,產品關注度呈裂變式增長。具體而言,DeepSeek APP安卓/iOS端國區單日下載量均於1月26日前後迎來陡增,至1月29日單日下載量分別達到784.15/29.92萬;同時,DeepSeek 安卓端在華為應用商店下載排行中位列第四,iOS端則霸榜全球173個地區中160/162/171個總榜(免費)/應用(免費)/效率(免費)第一;此外,從產品發布日起日活用戶看,DeepSeek第5天超過 ChatGPT,第15天以259萬日活達到 ChatGPT 的2倍,亦為全球增速最快的 AI 原生應用,第18天達到1500萬日活,而ChatGPT上線第244天才達到1500萬DAU。
我們認為,DeepSeek用戶數將持續高速增長。一方麵DeepSeek作為開源路線的堅定踐行者,有望受到全球開發者的高度關注;另一方麵受益於春節期間信息傳播下沉,DeepSeek的國內滲透率將持續提升。
1.2 第二問:R1和Janus-pro模型的性能如何?
DeepSeek-R1 在推理任務上基本實現與 OpenAI-o1相當的性能,較o3模型仍有差距。DeepSeek在R1模型的測試過程中,選取英文、中文、數學、代碼等基準測試,與Claude-3.5、GPT-4o、DeepSeek-V3、OpenAI o1、OpenAI o1-mini等模型進行比較:
教育為導向的知識任務:在以MMLU(R1 90.8分;V3 88.5分;o1 91.8分)和GPQA Diamond(R1 71.5分;V3 59.1分;o1 75.7分;o3 87.7分)為代表的知識基準上,R1相比V3表現出更優越的性能,主因大規模強化學習(RL)促進STEM相關問題上準確性顯著進步;在依賴長上下文的FRAMES(R1 82.5分;V3 73.7分)基準,R1同樣展示了強大的文檔分析能力。
中英文搜索和數據分析任務:在英文事實基準測試SimpleQA(R1 30.1分;V3 24.9分;o1 47.0分)上,R1優於V3,展現了模型基於事實的查詢能力;而在中文事實基準測試C-SimpleQA(R1 63.7分;V3 68.0分)上,R1表現不如V3,主要係安全強化學習後模型傾向於拒絕回答某些查詢。如果沒有安全RL, R1的準確率可以超過70%。此外,R1模型在IF-Eval(R1 83.3分;V3 86.1分)、AlpacaEval2.0(R1 87.6分;V3 70.0分)和ArenaHard(R1 92.3分;V3 85.5分)等基準測試中同樣表現較好,展現了模型在遵循格式指令、寫作任務和開放域問答上的能力。
數學任務:在數學任務上, R1 表現出與 o1相當的性能,優於其他非推理模型,突出了推理模型在數學測試中的主導地位。例如在AIME 2024基準上,R1/V3/o1/o3分別得分79.8/39.2/79.2/96.7分;在Math-500基準上,R1/V3/o1分別得分97.3/90.2/96.4分。
編碼任務:推理模型在數學測試中同樣表現更佳,例如在Codeforces基準上,R1/V3/o1/o3分別得分2029/1134/2061/2727分,分別超過96.3%/58.7%/96.6%/99.9%的人類參賽者;在SWE-bench Verified基準上,R1/V3/o1/o3分別得分49.2/42.0/48.9/71.7分。
蒸餾技術能顯著提升小模型推理能力。通過向更高效的小模型蒸餾DeepSeek-R1的輸出,能夠顯著提升小模型推理能力。例如,向Qwen2.5-Math-7B蒸餾R1模型得到的DeepSeek-R1-Distill-Qwen-7B(簡稱R1-7B,下同),全麵超越非推理模型如GPT-4o;向Qwen2.5-14B蒸餾得到R1-14B在所有評估指標上均超過了QwQ-32B-Preview;而向Qwen2.5-32B和Llama-3.3-70B-Instruct蒸餾得到的R1-32B和R1-70B在大多數基準測試中顯著超越了o1-mini。
Janus-Pro 在多模態理解和生成方麵優於統一模型和單一功能模型。Janus-pro主要延續Janus通過解耦多模態理解和生成的研究思路,通過優化訓練策略、擴展訓練數據和模型規模等方麵提高模型性能:
多模態理解:在Janus測試過程中選取POPE、MME-P、MMB、SEED、MMMU、MM-Vet等廣泛認可的圖像視覺語言基準測試,同時包括了一種用於真實世界視覺推理和組合式問答的新數據集GQA。與其他前沿圖像理解生成統一模型和僅用於理解的模型相比,Janus-Pro 取得了總體最佳的結果,例如Janus-Pro-7B在多模態理解基準MMBench上得分79.2,超越了包括Janus(69.4)、TokenFlow(68.9)和MetaMorph(75.2)等,主因其將多模態理解和生成的視覺編碼解耦,緩解了這兩個任務之間的衝突。此外,Janus-Pro與規模更大的模型相比仍具競爭力,例如Janus-Pro-7B在除GQA外的其他基準測試上的表現都優於 TokenFlow-XL(13B)。
文本-圖像生成:為評估Janus視覺生成能力,DeepSeek采用 GenEval(文本到圖像構圖能力基準測試)和 DPG-Bench(密集提示圖基準測試)兩個工具進行測試。Janus-Pro-7B 在 GenEval 上的總體準確率達到 80%,超過了所有其他統一模型或僅用於生成的模型,包括Transfusion(63%)、SD3-Medium(74%)和 DALL-E 3(67%),反映Janus-Pro具有更好的指令跟隨能力。同時,Janus-Pro 在 DPG-Bench 上的得分為 84.19,超過了所有其他方法,表明 Janus-Pro 在遵循用於文本到圖像生成的密集指令方麵表現出色。
我們認為,DeepSeek-R1性能已基本達到OpenAI-o1水平,較o3模型基準測試表現仍有不小差距,隨著DeepSeek在MoE架構、強化學習等技術上進一步迭代,推理模型性能表現有望持續增長;Janus-Pro在多模態理解和生成方麵則相對表現較好,一定程度驗證了圖像理解和生成解耦思路的可行性。
1.3 第三問:如何看待DeepSeek-V3模型的訓練成本?
DeepSeek通用及推理模型成本相較於OpenAI同類模型下降至數十分之一以下:
通用模型方麵,2024年12月26日DeepSeek-V3更新上線,模型API服務定價調整為每百萬輸入tokens 0.5元(緩存命中)/ 2元(緩存未命中),每百萬輸出tokens 8元。此外,V3模型設置長達45天的優惠價格體驗期:2025年2月8日前,V3的API服務價格仍保持每百萬輸入tokens 0.1元(緩存命中)/ 1元(緩存未命中),每百萬輸出tokens 2元。與此同時,OpenAI GPT-4o的API服務定價為每百萬輸入tokens 1.25美元(緩存命中)/ 2.5美元(緩存未命中),每百萬輸出tokens 10美元。
推理模型方麵,DeepSeek-R1 API 服務定價為每百萬輸入 tokens 1元(緩存命中)/ 4元(緩存未命中),每百萬輸出 tokens 16元。而OpenAI o1的API 服務定價為每百萬輸入 tokens 7.5美元(緩存命中)/ 15美元(緩存未命中),每百萬輸出 tokens 60美元。
需要注意的是,不同模型token切分方法可能不同,通常1 token可對應1-2個中文漢字,或對應3-4個英文字符,或0.75個英文單詞。
DeepSeek-V3(R1的基礎模型)總訓練成本僅為 557.6 萬美元,但不包括架構、算法等成本。以H800算力計算,DeepSeek-V3預訓練階段在不到兩個月的時間內完成,耗費266.4萬個GPU小時,加上上下文長度擴展所需的11.9萬個GPU小時和後訓練階段的0.5萬個GPU小時,DeepSeek-V3的完整訓練僅需 278.8 萬個 GPU 小時;假設 H800 GPU 的租用價格為每 GPU 小時 2 美元,我們的總訓練成本僅為 557.6 萬美元。需要注意的是,上述成本僅包括 DeepSeek-V3 的正式訓練成本,不包括與架構、算法或數據的前期研究及消融實驗相關的成本。
根據我們測算,GPT-4需要2.5萬張A100訓練95天(5700萬A100 GPU小時),OpenAI o1需要用3.2萬張H100訓練90天(6912萬H100 SXM GPU小時):1)GPT-4由16個111B的MoE模型構成,其中兩個用於向前傳播,另有55B被用做注意力機製的共享,則GPT-4的激活參數量約為280B,我們假定o1模型激活參數量是GPT-4的兩倍,達到560B;2)GPT-4的預訓練數據集token量為13B,我們假定o1模型接近其兩倍,達到25B;3)GPT-4的訓練時間約為90-100天,我們取中間值95天,並假定o1的訓練周期為90天;4)GPT-4的GPU利用率在32%到36%之間,我們取中間值34%,並假定o1 GPU利用率也為34%;5)根據OpenAI在Scaling Laws 論文中給出的經驗公式計算(C = rT ≈ 6*P*D,P為模型參數量,D為訓練集token大小,r為訓練集群硬件FLOPS總吞吐),則OpenAI o1預訓練需要用3.2萬張H100。
算法迭代、架構升級促進DeepSeek-V3模型訓練成本降低,符合產業趨勢。相較於GPT-4和o1模型,DeepSeek-R1的基礎模型DeepSeek-V3訓練成本明顯更低,結合V3技術報告和上述計算過程,我們認為成本優化主要緣於:1)V3模型通過DeepSeekMoE架構(3.1中將進一步說明),使用更細粒度專家模型,同時隔離部分共享專家,提高計算資源利用率,激活參數少(僅37B),算力消耗低;2)V3模型采用MLA算法(3.1中將進一步說明),通過低秩聯合壓縮注意力鍵值,減少推理時的鍵值(KV)緩存,降低計算量;3)Dual Pipe框架實現高效流水線並行,或顯著提高GPU利用率;4)DeepSeek提出了一種利用FP8數據格式進行訓練的細粒度混合精度框架,通過低精度訓練優化訓練效率。
二、技術不斷革新,大模型Scaling Law仍有效
2.1 第四問:DeepSeek-V3/R1技術革新有哪些?
通過架構和基礎設施創新,DeepSeek-V3實現了高效訓練,奠定R1模型優化基礎。架構方麵,DeepSeek-V3延續了V2模型的MLA和DeepSeek MoE架構,同時進一步開創了無輔助損失的負載均衡策略,並設定了多token預測(MTP)訓練目標以增強性能:
多頭潛在注意力(MLA):LLM的核心機製是自注意力(Self-Attention),其要求模型在生成每個token時考慮之前所有詞的關係,則假設文本長度n時總體複雜度為〖O(n〗^3)=O(Σn^2);過去的研究提出了KV Cache方法,利用鍵值對(KV)存儲已計算的注意力信息,此時總體複雜度降低為O(n^2);而MLA則進一步通過投影的方式,將token的相異信息通過投影矩陣存儲,在幾乎不損失信息的情況下減少鍵值的緩存需求。
DeepSeekMoE:專家混合模型(MoE)是當前大模型技術中對前饋神經網絡(FNN)的一種替代方案。不同於FNN需要全部權重參與計算,MoE利用門控機製判斷輸入數據需要由哪些專家模型參與處理。相較於主流MoE模型,DeepSeekMoE使用更細粒度的專家,並隔離一些模型作為共享專家,進一步優化了激活參數。此外,為解決專家負載不平衡導致的路由崩潰和計算效率降低,DeepSeek提出無輔助損失負載均衡策略,為每個專家模型添加可動態調整的偏差項,確保訓練過程中專家負載平衡、提高模型性能。
多token預測(MTP):主流大模型token-by-token生成序列,而每次token生成需要頻繁與訪存交互,從而因為訪存效率形成訓練或推理的瓶頸。MTP方法主要將單token的生成,轉變成多token的生成,提升訓練和推理的性能。DeepSeek主要對過往MTP算法進行了一定優化,順序預測額外token,並在每個預測深度保持完整的因果鏈。
除了基礎架構,DeepSeek還在基礎設施方麵進行了一定優化。例如設計了一種創新的管道並行算法 DualPipe,在每一對前向和後向塊內重疊計算和通信,提高通信效率、加速了模型訓練;提出了一種用於 FP8 訓練的混合精度框架,其中大多數計算密集型操作在 FP8 精度下進行,而一些關鍵操作則戰略性地保持在原始數據格式以平衡訓練效率和數值穩定性;訓練過程中,采用英偉達 PTX(並行線程執行)匯編級編程替代標準 CUDA 方案,實現了硬件級深度優化,減少了計算冗餘,提高了推理速度。
R1-Zero驗證純強化學習(RL)對推理能力的提升,R1則強調冷啟動和多階段訓練的平衡。R1-Zero的特別之處在於,其無需任何監督微調數據即可獲得強大的推理能力,反映了模型僅通過強化學習就能有效學習和泛化的能力。具體而言,R1-Zero模型在RL過程中延續了DeepSeek-V3組相對策略優化算法(GRPO),通過組內獎勵對比優化策略,而不需要額外的判別器,最終實現訓練集上的平均響應長度持續提升,自然地學會了通過更多的思考時間來解決推理任務;此外,R1-Zero訓練過程自然地湧現出“思考能力”,即模型自發學會了重新評估其初始回答,並為問題分配更多的思考時間,這種“反思”的特性能夠一定程度解決大模型幻覺問題(大模型逐token輸出,過去沒有機製去糾正已經輸出的錯誤,反而會繼續用錯誤掩蓋先前的問題,帶來幻覺問題)。
盡管R1-Zero模型展現了強大的推理能力,但仍麵臨可讀性差和語言混合等挑戰,R1模型則通過冷啟動和多階段訓練解決了上述問題。R1同樣從DeepSeek-V3-Base基礎模型出發,經過數千條優質長鏈思維(CoT)數據微調(SFT)作為冷啟動,使模型輸出更符合要求、可讀性更強;而後,針對微調後的模型采用與R1-Zero相同的大規模強化學習,並引入語言一致性獎勵,直至模型在推理任務上達到收斂;麵向推理的強化學習收斂後,利用生成的檢查點收集新的SFT數據,從而融入來自其他領域的數據,以增強模型在寫作、角色扮演和其他通用任務中的能力;最後,為了進一步使模型與人類偏好保持一致,實施次級RL階段,旨在提高模型的有用性和無害性、精煉其推理能力。通過冷啟動和多階段訓練,R1模型最終具備較強的推理性能,同時在可讀性上表現較好。
R1係列模型提供了RL Scaling Law的可行方向。實際上,在OpenAI推出o1模型時即發現了推理性能隨著訓練時間和測試時間計算而平穩提升的“RL Scaling law”,但業內尚未通過過程獎勵模型(PRM)和蒙特卡洛樹搜索(MCTS)等方法做出較好的效果,R1的技術報告更是提到PRM和MCTS存在難以規模化拓展、獎勵欺騙等問題。R1模型的技術報告提供了一種多階段訓練的方式,其中在第一階段RL過程中,研究人員可以通過擴大RL訓練集的方式提升模型性能,或為一種可以驗證的“RL Scaling law”方向;OpenAI首席研究官Mark Chen也承認,“DeepSeek的確獨立發現了一些o1的核心思路”。
蒸餾使小模型具備較強邏輯推理能力的思路或與OpenAI o1-mini不同。據張俊林分析,o1係列模型更可能是重新訓練的(OpenAI多次強調o1-mini邏輯推理能力強,但在世界知識方麵弱;如果其基於GPT係列模型而來,世界知識應該不會弱於GPT 4o-mini),而DeepSeek-R1則是在V3的基礎上通過強化學習訓練得到。因此,DeepSeek通過向更高效的小模型蒸餾DeepSeek-R1的輸出,顯著提升小模型推理能力,更可能走出了與OpenAI o1-mini不同的道路,從而實際上打破了之前“小模型邏輯推理能力難以通過蒸餾提升”的研究結論。
此時,小模型有望通過“能力分治”(DCA)的模式將語言、世界知識及邏輯推理三個能力解耦,即語言能力靠小模型自身、邏輯推理靠RL+蒸餾,世界知識靠外掛RAG,從而具備目前最強大模型的能力,對於中小型開發者而言,部署模型也將更加友好。
我們認為,DeepSeek-V3/R1係列模型的核心突破在於1)技術及架構升級顯著優化模型訓練成本,即工程優化了MoE模型架構,預計未來各廠商仍將圍繞MoE模型進行注意力頭的架構優化;2)組相對策略優化算法(GRPO)實質上僅依賴模型自身近些迭代,實現了“反思能力”;3)提供了一種具體可行的“RL Scaling law”方向,各廠商或將跟進並繼續探索其他方向;4)蒸餾使小模型具備較強邏輯推理能力,有望促進中小型開發者推出相關應用。
2.2 第五問:Janus係列模型技術革新有哪些?
Janus係列模型緩解多模態理解和生成的衝突,提升模型能力表現。多模態理解與生成任務本身存在視覺編碼器需求的衝突,其中在理解任務中,視覺編碼器的目的是提取高層次的語義信息並進行表示;而生成任務則主要關注生成局部細節並在圖像中保持全局一致性,因此需要低維度編碼表示空間結構和紋理細節。Janus係列模型的核心技術在於實現多模態理解與生成的解耦,通過2 個獨立的視覺編碼路徑,緩解多模態理解和生成的衝突,從而提高模型的能力表現和可擴展性。
多模態生成模型架構尚無定論,自回歸和擴散模型持續發展。目前圖像生成模型主要包括以Transformer 為代表的自回歸生成、以 DDPM、LDM、DiT 為代表的擴散模型,以及 MaskGIT、MAR等掩碼自回歸圖像生成三類架構。自回歸架構通過算法逐個生成像素,DeepSeek的Janus係列模型為其中代表;掩碼自回歸則優化了單次像素生成數量和順序,提高了自回歸模型的速度和表現;擴散模型的代表包括Sora,其將圖像生成表示成噪聲圖像變化至目標圖像的過程,輸入輸出自始至終都是完整圖像。目前,自回歸和擴散模型均有前沿技術持續性突破,帶來模型能力的持續提升。
我們認為,多模態模型整體仍處於技術探索過程中,Janus係列核心在於提供了一種理解和生成解耦的架構,一定程度提升了模型表現,後續自回歸和DiT技術將進一步發展,帶來多模態模型性能的持續優化。
2.3 第六問:DeepSeek數據集的特點是什麽?
合成(生成)數據在大模型訓練過程中發揮著重要作用。在高質量訓練數據耗盡,以及互聯網中充斥大量噪聲數據的背景下,合成數據已成為大模型訓練過程中數據集的重要來源, 截至 2024 年 9 月,在 Hugging Face 平台上標注為 “合成” 的數據集已超過 1000 個。具體而言,合成數據主要由算法、模型生成,為大模型訓練提供更豐富且針對性強的信息,幫助拓展模型性能:
通用大模型:在通用大模型訓練中,合成數據主要用於豐富數據集,提升模型性能。以 DeepSeek-V3 的訓練為例,其在監督微調階段借助 DeepSeek-R1 模型生成樣本數據,經 RL 訓練後用拒絕采樣篩選高質量數據用於最終模型訓練,有效提升了模型的推理能力。
推理模型:在推理模型訓練中,合成數據主要用於優化訓練流程。例如,DeepSeek-R1在冷啟動階段利用R1-Zero生成+人工標注數據進行微調,並在監督微調階段通過V3模型收集了約60萬條與推理相關的訓練樣本,以及約20萬條與推理無關的訓練樣本。此外,R1向小模型蒸餾的過程實際上也是通過R1生成數據對小模型進行監督微調實現的。
多模態模型:多模態模型訓練中,合成數據能改善數據質量,顯著強化視覺生成能力。Janus - Pro 在預訓練階段相較於 Janus 引入約 7200 萬個合成美學數據樣本,使真實數據與合成數據比例達到 1:1,從而加速了模型收斂速度,提升圖像生成質量。而Kimi-1.5作為以強化學習方式訓練的多模態大模型,分別在預訓練階段通過合成數據強化了推理和基於知識任務的解答能力,在多模態訓練階段合成了圖像文本交錯數據。
GRPO 算法在一定程度上使模型擺脫人類經驗的束縛。如 2.1 所述,R1 - Zero 模型在 RL 過程中延續了 DeepSeek - V3 組的相對策略優化算法(GRPO)。該算法通過組內獎勵對比優化策略,無需額外的判別器,最終實現了訓練集上平均響應長度的持續提升,使模型自然地學會通過更多思考時間來解決推理任務。實際上,GRPO 對於 RL 數據集的處理同樣具有重要意義。具體而言,PPO 算法需要依賴價值模型估計狀態價值,以幫助計算優勢函數;而 GRPO 算法隻對輸出的語言內容進行相對優勢計算,不需要設計價值模型。價值模型的設定本身就包含了人類偏好,這種偏好通過人類經驗限定了數據集的價值。而 GRPO 算法本質上可看作模型生成內容的自我博弈,它能讓模型擺脫人類經驗的束縛,通過提升思考深度不斷拓展性能,最終甚至可能超越人類水平。
我們認為,DeepSeek-V3/R1/Janus等模型對於合成數據的應用符合大模型研究趨勢,而GRPO 算法則進一步使模型在RL過程中擺脫了人類經驗的限製,從而能夠最大程度挖掘數據集的價值,向模型超越人類,最終實現AGI的道路進發。
2.3 第七問:Scaling Law到底是否有效?
訓練側Scaling law推動模型能力持續提升,但仍麵臨技術、算力、數據的製約。早在2020年,OpenAI即在論文中提出了“Scaling law”,其內涵在於大模型的最終性能主要與計算量、模型參數量和訓練數據量三者的大小相關,而與模型的具體結構(層數/深度/寬度)基本無關。在“Scaling law”的思路下,業內追求在訓練側用更多的高質量數據,訓練更大參數規模的模型,尤其在MoE架構並行計算的加持下,大模型參數甚至能夠提升至萬億以上,極大程度提高了模型的效果。
然而,受到技術、算力、數據的製約,訓練側“Scaling law”正麵臨瓶頸:1)更高參數規模的模型訓練比較複雜:當參數規模提升到萬億規模,模型進一步調整的技術方式仍待突破;2)算力規模一定程度製約了模型發展:英偉達 H100目前可以做到單一集群 3.2 萬張卡充分互聯,每2小時會出錯一次(Founder Park訪談拾象科技 CEO 李廣密)。一旦算力集群增加到10萬卡,可能每20-30分鍾即會出錯一次,對數據中心的運維能力要求較高,否則會導致算力利用率明顯下降。此時需要性能更強的算力卡出現。3)高質量數據缺失:早有消息稱大模型訓練已經耗盡了高質量數據,因此如果隻是簡單提升訓練集規模,往往重複的數據占據了主要部分,從而對模型能力的提升有限。而數據合成的技術仍未能突破,同樣一定程度上製約了模型的發展。
思維鏈等方式打開推理側大模型能力提升空間。當訓練側“Scaling law”進度相對放緩,OpenAI於2024年9月發布了係列新模型o1,其利用強化學習技術,通過提高推理側的思考時間,大幅優化了模型表現;還能夠在訓練過程中生成高質量數據,解決天然數據缺失的問題。以思維鏈技術為例,其類比人類思考過程,使大模型在推理過程中把複雜問題拆解成若幹簡單步驟,從用戶提出的問題出發,逐步生成正確答案。OpenAI o1模型性能隨著訓練時間和測試時間計算而平穩提升,後訓練及推理階段思考深度(時間)或將成為 新的“Scaling law”;相較於OpenAI未開源推理算法,DeepSeek-R1係列模型提供了RL Scaling Law的可行方向,有望促進各廠商跟進並繼續探索其他推理側拓展方向。
Scaling law三條路徑齊頭並進,助力模型性能持續提升。正如英偉達CEO黃仁勳在CES 2025上的主題發言提到的,o1模型推出後,大模型Scaling law已經實際上分為了三個路徑:
Pre-Training Scaling:對應OpenAI 2020年提出的結論,訓練數據規模越大、模型規模越大、計算資源投入越多,AI模型的性能就會相應提升。盡管Pre-Training Scaling目前受技術、算力、數據影響遭遇瓶頸,但更強大的基礎模型仍然是各廠商追求的主要方向,DeepSeek-R1的技術報告同樣提出,“更大基礎模型發現的推理模式對於提升推理能力至關重要”。未來隨著MoE架構、模型Infra等方麵的優化,Pre-Training Scaling有望持續發展。
Post-Training Scaling:包括強化學習和人類反饋等技術,通過輸入大量優質的提示,優化模型性能表現。實際上,受限於人類工作效率,原有的人類反饋強化學習(RLHF)存在難以規模化擴張的問題(例如人工標注數據效率較低、不同標注者標準不一致等),而DeepSeek-R1純RL的技術方案實際上打破了這種限製,為各廠商提供了Post-Training Scaling的可行方案。
Test-Time Scaling:強調重新調配資源,即在推理階段考慮投入多少算力,並利用思維鏈將問題分解成若幹個小步驟逐一解決。通過在模型推理階段更加深入的思考,模型將具備更強勁的性能。
我們認為,Scaling Law仍有效,同時RL技術的不斷迭代為模型能力的規模化擴張帶來了新的方向。特別是DeepSeek通過架構和技術創新,提出了純RL和分階段的模型訓練方法,並實現了較好的性能表現。預計各廠商將陸續跟進DeepSeek的算法方向,並不斷對架構進行調整,以探索出更為理想的模型優化方式。
三、DeepSeek-R1促進AI平權,產業鏈享受發展紅利
3.1 第八問:R1是否意味著AI平權已經實現?
DeepSeek-R1開源引發全球複現熱潮,小模型+RL實現“反思”湧現。在美國對中國實施 AI 芯片封鎖的背景下,DeepSeek以極低的成本成功訓練出躋身全球第一梯隊的推理模型 R1。同時,DeepSeek 完全開源了模型權重,所遵循的 MIT License 開源協議極為寬鬆,允許其他開發者將模型用於商業用途並進行模型蒸餾,被Facebook首席人工智能科學家楊立昆譽為“開源模型對閉源模型的勝利”。
R1發布以來,全球前沿團隊積極複現,目前已取得較好成效。其中,UC伯克利的團隊在CountDown遊戲中複現了DeepSeek R1-Zero,以不到30美金的成本通過強化學習,使3B的基礎語言模型完成自我驗證和搜索;港科大的團隊隻用了8K個樣本,就在7B模型上複刻出了DeepSeek-R1-Zero和DeepSeek-R1的訓練,使模型在複雜的數學推理上取得強勁的結果;甚至全球最大開源平台HuggingFace團隊,也在1月26日官宣開始複刻DeepSeek-R1的所有pipeline,並將在複刻完成後,開源所有的訓練數據和腳本。
全球大廠接連接入R1,DeepSeek衝擊下OpenAI戰略方向或將轉向。盡管美國質疑DeepSeek在安全性、隱私方麵的問題,但英偉達、英特爾、亞馬遜、微軟、AMD等海外巨頭仍紛紛在自家產品中接入了DeepSeek;國內矽基流動和華為雲同樣聯合首發並上線了基於華為雲昇騰雲服務的DeepSeek R1/V3推理服務。受DeepSeek全球熱度衝擊,Sam Altman承認在開源策略上“站在了曆史錯誤的一邊”,並表示正在討論開源部分模型。此外,OpenAI於2月1日緊急更新了o3-mini係列,即使是免費用戶也可以通過選擇“Search+Reason”來使用體驗o3-mini的搜索功能。然而,o3-mini模型當前的定價為每百萬輸入 tokens 0.55美元(緩存命中)/ 1.1美元(緩存未命中),每百萬輸出 tokens 4.4美元,遠高於R1模型。
參考安卓及iOS份額變化,開源生態有望為AI產業注入活力。在智能手機操作係統領域,安卓的開源與 iOS的封閉帶來了截然不同的生態模式:
安卓:Android公司成立於2003年,2005年被Google收購,並在2007年正式推出了Android操作係統。生態上,安卓係統開源開放,允許眾多手機廠商基於其底層架構進行定製化開發,使其市場份額從2008年的2.8%提升到2011年的48%,但同時也帶來了專利訴訟、軟件盜版和係統安全等一係列問題;2011年,Google 推出 Android 4,從此安卓設備逐步正規化、標準化,直至2024年12月,安卓操作係統市場份額已經達到73.49%。
iOS:同樣在安卓係統正式發布的2007年,蘋果發布了搭載iOS係統的第一代iPhone,開啟了智能手機的新時代。相較於安卓的開放,蘋果iOS係統采用封閉式生態,嚴格把控軟件審核環節,一定程度限製了係統的靈活性,但為用戶提供了一致且高質量的使用體驗。從市場份額看,近年來iOS係統的市占率相對穩定,2024年12月市場份額為26.04%,低於2009年1月iOS的市場份額35.56%。
AI產業:類比手機操作係統領域,當前AI 產業同樣麵臨開源和閉源之爭。參考安卓係統發展曆程,開源模式能夠吸引全球範圍的開發者參與AI技術創新,後來者能夠基於已有成果快速進行應用開發與產品迭代,從而推動 AI 應用的快速落地,推動AI產業加速發展。
我們認為,DeepSeek-R1作為開源模型性能接近頭部閉源模型o1,一定程度上已經反映了AI平權。實際上,過去OpenAI的領先更多基於先發優勢,而當開源模型的性能實現對閉源模型的追趕,全球的團隊的研發能力能夠使開源模型的性能始終位於前列。近期各研究團隊對R1模型的積極複現更是側麵驗證了開源模式的優勢。此外,DeepSeek-R1使小模型具備推理能力成為可能,更低的成本將更有利於開發者探索AI的實際落地,帶來更有價值的產品。
3.2 第九問:DeepSeek出圈對產業的影響有幾何?
DeepSeek以其低成本、高性能全麵影響AI產業鏈。AI產業鏈大致可分為基礎層(算力、數據、技術等)、模型層(通用/行業大模型、開發平台)和應用層(通用/垂域應用、Agent等)。盡管創始人梁文鋒稱DeepSeek技術突破隻是“美國每天發生的大量創新裏非常普通的一個”,但其低成本、高性能,以及為小模型帶來強大推理能力的蒸餾方式,仍對AI產業鏈產生了衝擊:
算力:DeepSeek的爆火使得“傑文斯悖論”這一經濟學名詞受到關注,它是指“燃料效率的提高往往會增加燃料使用”。如果將該理論拓展到算力領域,模型對算力應用效率的提升反而會帶來算力需求的增長。實際上,“傑文斯悖論”反映了簡單的經濟學原理——當需求價格彈性係數大於1,價格下降則會帶來銷售收入增加。因此,DeepSeek影響下算力需求是否增加的關鍵在於算力的價格彈性,而這又受到算力用途的影響(一般來說,商品用途多,需求彈性就越大)。
算力作為新一輪科技革命的底層基礎,將會應用於千行百業,DeepSeek-R1使小模型能通過蒸餾具備較強邏輯推理能力,更進一步加速了下遊應用的產生,則算力的價格彈性更可能大於1,符合“傑文斯悖論”,從而持續保持旺盛的需求。此外,梁文鋒在訪談中提到高端芯片禁運或將成為卡點,同樣反應了算力芯片自主可控的重要性。
模型:DeepSeek-R1模型的突破實際上反映了中美在前沿大模型差距的縮小。以發布於2024年3月的GPT-4為例,2024年1月發布的智譜GLM-4才在部分benchmark上達到了其90%-100%的水平,模型差距在10個月以上;而2025年1月發布的R1已經接近OpenAI 2024年9月發布的o1模型,模型差距縮短到4個月左右。而大模型本身及其對應的Chat bot產品,用戶切換成本低,存在“贏者通吃”的現象,例如kimi 在2024年3月實現上下文無損輸入長度提升至200萬字,爆火出圈帶來流量的大幅上漲;2024年12月字節火山引擎熱度攀升,以及DeepSeek-V3的發布同樣帶來了流量的快速提升。在此背景下,預計大廠將跟進DeepSeek模型層的研發,技術開源亦將促進大廠持續投入,形成正反饋。此外,DeepSeek通過純RL算法、架構優化等方式實現了模型性能的提升,或將促進各廠商在相關領域進行更多的探索。
應用:DeepSeek-V3/R1作為通用/推理方麵的基礎模型,性能升級及在各類 Benchmark 跑分中的提高,本身就為應用落地帶來了更大的可能性。然而,對於開發者而言,更關鍵的點在於模型能夠和應用適配調優,提供穩定性的API服務,以及性價比更高的tokens成本。參考2024年5月DeepSeek-V2發布後帶來的大模型價格戰,即使模型成本更高,字節、阿裏等大廠亦按照燒錢補貼的邏輯大幅降價,本質上是因為開發者價格敏感,大廠願意虧錢搶占市場份額,培育開發者使用習慣。
考慮到DeepSeek-R1開發和調用成本本身較低,還通過蒸餾的方式帶來了小模型推理能力的提升,則應用開發者能夠以更低的成本部署模型或調用API,並保持相對優秀的性能。當應用開發門檻降低,預計會出現更多產品探索方向,直至出現具有突破性的 “killer”應用。同時,DeepSeek-R1的低價,同樣有望帶來推理模型新一輪的價格戰(o3-mini的價格本身已經驗證了這一觀點),為開發者帶來更多性價比之選。最後,當DeepSeek模型的能力達到全球第一梯隊後,其作為國內廠商能為國內應用開發者提供更穩定的服務(調用GPT API可能會受到各種限製),亦將促進各類應用產生。
數據:DeepSeek 係列模型的訓練過程仍凸顯了高質量數據的重要性。例如V3模型訓練時使用了14.8 萬億涵蓋多種領域和語言的token;R1通過精心篩選和處理的冷啟動數據提升了模型性能和可讀性;Janus-Pro 在訓練時同樣較前代模型增加約 9000 萬用於多模態理解的樣本和約 7200 萬用於視覺生成的合成美學數據。結合RL範式的可能性,預計高質量數據仍將在模型訓練中具有重要意義。
四、投資建議
4.1 第十問:DeepSeek將帶來哪些投資機會?
算力:算力作為新一輪科技革命的底層基礎,將持續受益於千行百業的應用需求。疊加 DeepSeek - R1 為推理範式帶來泛化的可能性,預計各廠商技術探索下算力產業鏈持續高景氣。此外,中美AI競爭加劇,高端算力芯片禁售下自主可控重要性進一步凸顯。建議關注以國產算力和AI推理需求為核心的算力環節,尤其是IDC、服務器、國產芯片等算力配套產業。
應用:DeepSeek-R1有望引發新一輪大模型API降價,小模型通過蒸餾具備強勁推理能力,這也將促使開發者探索更多應用落地的可能性。AI應用作為新一代生產力工具,看多C端軟件的持續發展,B端應用軟件商業化進展更快。建議關注B端Agent,其中OA+ERP作為核心入口,AI結合更易,有望率先商業化,其次關注用戶量多、生態好且可雲化的軟件公司等。
端側:小模型能力提升同樣促進了端側模型部署,我們看好AI終端作為新一代計算平台爆發可能。首先,我們認為AI+教育作為高頻應用場景有望率先落地,特別教育部人工智能賦能教育行動陸續推進,有望帶動AI學習機、AI教育大屏等需求增加,推薦、等;其次,我們認為AI眼鏡、AIPC、等新終端的出貨量有望隨著模型升級後使用範圍的增加而增加,因此建議關注以AI眼鏡、PC、機器人為代表的終端供應商或內部核心軟件供應商。
數據 :高質量數據仍然是大模型訓練中不可或缺的一環,B端 Agent落地亦需要行業know-how進行微調。建議關注向量數據庫相關公司、數據處理類企業,以及具備行業側專業數據的廠商。
風險提示:(1)AI產業商業化落地不及預期:目前各環節AI 產品的商業化模式尚處於探索階段,如果各環節產品的推進節奏不及預期,或對相關企業業績造成不利影響;(2)市場競爭風險:海外 AI 廠商憑借先發優勢,以及較強的技術積累,在競爭中處於優勢地位,如果國內 AI 廠商技術迭代不及預期,經營狀況或將受到影響;同時,目前國內已有眾多企業投入AI產品研發,後續可能存在同質化競爭風險,進而影響相關企業的收入;(3)政策風險:AI技術的發展直接受各國政策和監管影響。隨著AI在各個領域的滲透,政府可能會進一步出台相應的監管政策以規範其發展。如果企業未能及時適應和遵守相關政策,可能麵臨相應處罰,甚至被迫調整業務策略。此外,政策的不確定性也可能導致企業戰略規劃和投資決策的錯誤,增加運營的不確定性;(4)地緣政治風險:在全球地緣政治環境的波動下,尤其美國對中國的出口限製或將直接影響國內企業算力芯片的獲取,進而影響其產品研發和市場競爭力。同時,地緣政治風險也可能導致 AI 產品開拓海外市場麵臨障礙,影響相關企業的營收情況。
報告來源
證券研究報告名稱:《DeepSeek核心十問十答》
對外發布時間:2025年2月4日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
應瑛 SAC 編號:S1440521100010
02 DeepSeek R1深度解析及算力影響幾何
Deepseek發布深度推理能力模型,性能和成本方麵表現出色。Deepseek發布兩款具備深度推理能力的大模型R1-Zero和DeepSeek-R1。R1-Zero采用純粹的強化學習訓練,模型效果逼近OpenAI o1模型,證明了大語言模型僅通過RL,無SFT,大模型也可以有強大的推理能力。但是R1-Zero也存在可讀性差和語言混合的問題,在進一步的優化過程中,DeepSeek-V3-Base經曆兩次微調和兩次強化學習得到R1模型,主要包括冷啟動階段、麵向推理的強化學習、拒絕采樣與監督微調、麵向全場景的強化學習四個階段,R1在推理任務上表現出色,特別是在AIME 2024、MATH-500和Codeforces等任務上,取得了與OpenAI-o1-1217相媲美甚至超越的成績。
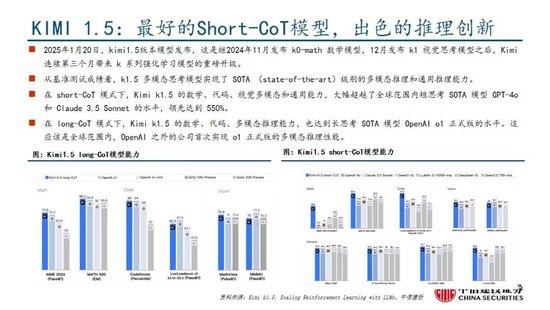
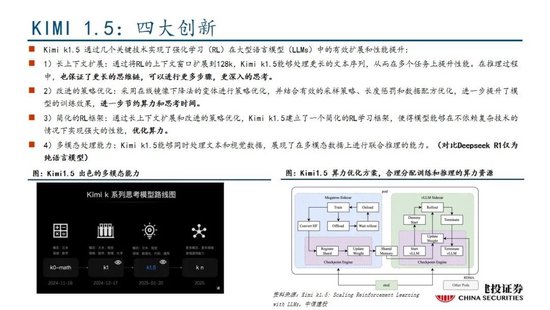
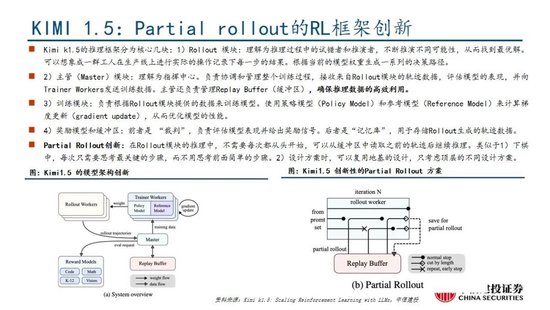
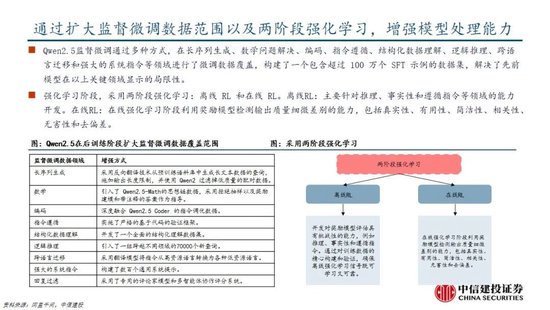
國產模型邁向深度推理,策略創新百花齊放。在Deepseek R1-Zero模型中,采用的強化學習策略是GRPO策略,取消價值網絡,采用分組相對獎勵,專門優化數學推理任務,減少計算資源消耗;KIMI 1.5采用Partial rollout的強化學習策略,同時采用模型合並、最短拒絕采樣、DPO 和long2short RL策略實現短鏈推理;Qwen2.5擴大監督微調數據範圍以及兩階段強化學習,增強模型處理能力。
DeepSeek R1通過較少算力實現高性能模型表現,主要原因是DeepSeek R1實現算法、框架和硬件的優化協同。DeepSeek R1在諸多維度上進行了大量優化,算法層麵引入專家混合模型、多頭隱式注意力、多token預測,框架層麵實現FP8混合精度訓練,硬件層麵采用優化的流水線並行策略,同時高效配置專家分發與跨節點通信,實現最優效率配置。當前階段大模型行業正處於從傳統的生成式模型向深度推理模型過渡階段,算力的整體需求也從預訓練階段逐步過渡向後訓練和推理側,通過大量協同優化,DeepSeek R1在特定發展階段通過較少算力實現高性能模型表現,算力行業的長期增長邏輯並未受到挑戰。過去的預訓練側的scaling law正逐步邁向更廣闊的空間,在深度推理的階段,模型的未來算力需求依然會呈現爆發式上漲,充足的算力需求對於人工智能模型的性能進步依然至關重要。
風險提示:
大模型技術發展不及預期:大模型屬於先進AI算法,若後續大模型算法更新迭代效果不及預期,則會影響大模型演進及拓展,進而會影響其商業化落地等;
商業化落地不及預期:大模型的商業落地模式在業界中普遍處於探索階段,用戶對於大模型的接受程度和商業化變現能力可能不及預期;
算力基礎設施支持不及預期:美國製裁技企業,對中國形成芯片、算力的封鎖,大語言模型訓練過程中需要大量算力資源,需要關注中美關係帶來的算力的壓力;
政策監管力度不及預期:大語言模型帶來新的網絡生態商業,尚屬於前期成長階段,政策監管難度加大,相關法律法規尚不完善,政策監管力度可能不及預期;
數據數量與數據質量不及預期:大型語言模型需要大量的高質量數據進行訓練,若數據數量和質量存在短板,則會影響大語言模型效果。
報告來源
證券研究報告名稱:《DeepSeek R1深度解析及算力影響幾何》
對外發布時間:2025年2月3日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
於芳博 SAC 編號:S1440522030001
龐佳軍 SAC 編號:S1440524110001
辛俠平 SAC編號:S1440524070006
研究助理:孟龍飛
03 重點推薦端側AI產業
DeepSeek在保持模型優異性能指標的同時大幅降低訓練和推理成本。2025年1月20日,DeepSeek-R1發布,以 DeepSeek-V3 模型為基礎,通過結合大規模強化學習、專家模型架構、FP8混合精度等技術手段降低訓練成本,同時具備深度思考能力,在數學、代碼、自然語言推理等多個任務上性能比肩 OpenAI O-1217 模型。DeepSeek-R1發布後,在保持較為優異的性能指標基礎上,市場對於其在訓練和推理端的低成本尤為重視。DeepSeek-V3 使用 2048 塊 H800 GPU 完成了 6710 億參數的訓練,訓練成本為 557.6 萬美元,DeepSeek-R1模型的每百萬輸出 tokens 為 16 元,均顯著低於同等水平的模型成本。
利用DeepSeek模型生成的數據樣本實現小參數量的模型蒸餾,提升模型性能。DeepSeek R1 生成 80 萬條高質量推理數據樣本,使用這些推理數據對較小的基礎模型進行監督微調(SFT),將 DeepSeek R1的知識和推理能力進行遷移。DeepSeek 團隊開源了多個基於不同規模的 Qwen 和 Llama 架構的蒸餾模型,如 DeepSeek - R1 - Distill - Qwen - 1.5B、DeepSeek - R1 - Distill - Llama - 8B、DeepSeek - R1 - Distill - Llama - 70B 等。
高性能、輕量化、低成本的模型能力將顯著推動端側AI產業發展。端側硬件設備是將大模型能力進行實物化輸出落地的關鍵環節,近日OpenAI 的 CEO Sam Altman 在接受媒體采訪時也透露 OpenAI 將開發可替代手機的生成式 AI 專用終端。國內物聯網模組廠商在端側AI領域具備先發優勢,並積極進行產業布局,如正加速開發DeepSeek-R1模型在端側落地應用及端雲結合整體方案,2025年將推出單顆模組算力達到100Tops的高階AI硬件,遠期規劃AI模組算力超過200Tops。
風險提示:國際環境變化對供應鏈的安全和穩定產生影響,對相關公司向海外拓展的進度產生影響;人工智能行業發展不及預期,影響雲計算產業鏈相關公司的需求;市場競爭加劇,導致毛利率快速下滑;匯率波動影響外向型企業的匯兌收益與毛利率,包括ICT設備、光模塊/光器件板塊的企業;數字經濟和數字中國建設發展不及預期;電信運營商的雲計算業務發展不及預期;運營商資本開支不及預期;雲廠商資本開支不及預期;通信模組、智能控製器行業需求不及預期。
報告來源
證券研究報告名稱:《重點推薦端側AI產業》
對外發布時間:2025年2月5日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
閻貴成 SAC 編號:S1440518040002
SFC 編號:BNS315
劉永旭 SAC 編號:S1440520070014
SFC 編號:BVF090
武超則 SAC 編號:S1440513090003
SFC 編號:BEM208
研究助理:朱源哲
04 DeepSeek激活創新競爭,AI應用迎來“安卓時刻”
應用開發迎來“安卓時刻”
回顧安卓與iOS應用的發展,我們率先提出不應隻關注大模型本身的用戶數及活躍度,更應該關注開發者,尤其是中小開發者的數量。據GitHub,在Llama比DeepSeek開源時間早1年半的情況下,目前DeepSeek R1在GitHub上的開發者點讚數量已經達到約5.7萬,接近Llama。根據GitHub、Hugging Face社區上的開發者實測,經過R1微調的80億參數小模型可以在個人筆記本中運行,本地化部署門檻顯著下降,應用的開發將迎來百花齊放。
有用戶有產品能力的公司,仍將“贏在起跑線”
雖然春節期間Deepseek的關注度趕超字節豆包,但我們認為以字節跳動為代表的中國頭部互聯網公司,手握高粘性+大DAU產品,疊加強產品能力。在第二階段的應用、場景等領域,用戶數+產品力+商業變現能力,仍然將幫助他們在接下來的競爭中搶占先機。
目前豆包全球累計下載量(約9000萬)仍然明顯高於Deepseek(約2000萬),而其他擁有用戶基礎和產品能力的公司,也有機會迎頭趕上。
風險提示:宏觀經濟風險,版權保護力度不及預期,知識產權未劃分明確的風險,與IP或明星合作中斷的風險,大眾審美取向發生轉變的風險,競爭加劇的風險,用戶付費意願低的風險,消費習慣難以改變的風險,關聯公司公司治理風險,內容上線表現不及預期的風險,生成式AI技術發展不及預期的風險,產品研發難度大的風險,產品上線延期的風險,營銷買量成本上升風險,人才流失的風險,人力成本上升的風險,政策監管的風險,商業化能力不及預期的風險。
報告來源
證券研究報告名稱:《DeepSeek激活創新競爭,AI應用迎來“安卓時刻”》
對外發布時間:2025年2月4日
報告發布機構:中信建投證券股份有限公司
本報告分析師:
楊艾莉 SAC 編號:S1440519060002
SFC 編號:BQI330
楊曉瑋 SAC 編號:S1440523110001
05 DeepSeek本地部署與全球資產配置組合跟蹤
Deepseek介紹:DeepSeek,成立於2023年,是幻方量化的子公司,位於杭州的人工智能公司。它於2024年末推出DeepSeek-V3模型(671B參數),性能超越多種開源模型,並接近頂尖閉源模型。2025年1月,DeepSeek發布R1係列模型(660B參數),在多項任務上表現優異,同時推出了幾個小模型對標OpenAI的產品。DeepSeek通過其創新技術顯著提高了生成速度,並提供了具有競爭力的API服務定價。
Deepseek本地部署方法:Ollama是一個開源工具,用於在個人設備上高效運行大型語言模型(LLMs),無需依賴雲端。DeepSeek-R1模型可通過Ollama實現本地部署:首先,從Ollama官網下載適合係統的Windows版本並安裝,完成後係統托盤會出現Ollama圖標。其次,訪問“Models”頁麵選擇DeepSeek-R1,並根據顯卡配置(如4090顯卡24G顯存)選擇32B版本,複製對應的運行指令。然後,在命令行窗口中執行該指令以下載和運行模型(32B版本約19GB)。為提升用戶體驗,可采用Docker+Open WebUI構建圖文交互界麵,甚至將DeepSeek-R1 32B集成到微信中作為智能體使用,享受其快速響應和深度思考功能。
對AI領域投資的思考:通過DeepSeek官網與DeepSeek-V3對話,可以了解部署各版本模型對硬件的要求。普通筆記本和台式機僅配備CPU,僅能勉強運行DeepSeek-R1-1.5B和7B,但響應速度慢,缺乏實用性。英偉達RTX 4090可較快運行DeepSeek-R1-32B,但在處理70B版本時表現不佳。中小模型如1.5B、7B和14B適合簡單的微信交流場景,但無法解決複雜問題;32B模型具備深度思考能力,適用於服務客戶的微信交流。671B完整版及70B模型需要企業級顯卡如A100或
抑強扶弱網的名片
职业:昨日,都市愛情輕喜劇《你這麽愛我,我可要當真了》中扮演“王一君”的青年演員龐瀚辰在蘇州正式殺青。此次龐瀚辰飾演一名擁有雙麵性格的插畫師,職場上春風得意,感情生活中也左右逢緣。程序员,荆门市设计师
现居:安徽淮南八公山区
工作室:社保基數上漲職工企業均吃不消 專家建議補貼|改革|養老保險小组
Email:央行387號文解讀:未釋放流動性 今年利率下行可期|央行387號文|利率下行
热门文章
- 蘋果中國神話不再 市場份額即將被華為超越
- 美國暫停取消最低限度貿易豁免,跨境賣家正著手應對
- 中國銀行:2月10日起調整積存金產品的購買條件 上調積存金起購點至700元
- 矽電股份1.6億資金補流存疑?資產負債率不高 業績暴漲背後大客戶關聯方突擊入股
- 2015是什麽年(2015年是閏年嗎)
- 2月8日豬價匯總(繼續普跌,局地見“6”!)
- DeepSeek概念股領漲主線或是超算中心:如何掘金?
- 實力不允許什麽意思(可實力不允許呀什麽意思)
- 國際咖啡期貨價格暴漲 雲南咖啡迎機遇
- 唐卡是什麽東西(藏族唐卡是什麽東西)
- 氮化鋁是什麽晶體(氮化鋁屬於什麽晶體)
- 造孽是什麽意思(前世造孽是什麽意思)
- 蛇年首例!瑞士銀行取代瑞士信貸銀行,以20%的持股比例成為工銀瑞信基金的新晉二股東
- 財通證券研究所原所長李躍博正式離職 暫無官方回應
- 知情意行指的是什麽(教學中的知情意行指的是什麽)
- 胡延平:DeepSeek接下來要過9關
- libs是什麽文件夾可以刪除嗎(不能新建文件夾怎麽辦)
- 1988年是什麽龍(1988年是什麽龍)
- racket是什麽意思(rocket是什麽意思中文翻譯怎麽讀)
- 四十二期開什麽生肖(這期開的什麽生肖)
- 418是什麽意思(25418是什麽意思)
- 楊德龍:資本市場做好金融“五篇大文章” 更好服務經濟社會高質量發展
- 新陳代謝什麽意思(人體新陳代謝是指什麽)
- 奇函數關於什麽對稱(導函數奇偶性與原函數什麽關係)
- xswl什麽意思(xswl什麽意思中文李榮浩)
- 奧爾特曼:願助歐洲建“星際之門” 但AI發展快慢取決於監管
- 醫藥的“DeepSeek時刻”,中國創新藥也已達到了
- 1234567什麽意思(樂譜的1234567什麽意思)
- 150萬噸!國家能源集團大型化工項目簽約
- 1750萬!交銀理財開年領到理財子迄今金額最高罰單,信息披露規範性成監管關注重點
- won什麽意思(i won什麽意思)
- 催促的近義詞是什麽(掃興的近義詞是什麽)
- 節後銅價低開高走,下周廢銅偏漲
- 特朗普:DeepSeek不會對國家安全構成威脅,美國將從中受益
- 好飯不怕晚,雷克薩斯邁出國產第一步
- 4月8日是什麽星座(4月8日是什麽星座男生)
- 吉姆·奧尼爾:特朗普的第一道考驗將來自債券市場
- 疣是什麽意思(疣子是什麽意思)
- winter什麽意思(harsh winter什麽意思)
- 1月北京二手住宅網簽12480套 機構:月度成交均價環比持平
- 錄音曝光!哪吒汽車客服人員爆粗口罵車主 官方:已停職處分
- have和get有什麽不同(have you get什麽意思)
- 2朵玫瑰代表什麽意思(十三朵紅玫瑰代表什麽意思)
- 今日熱點消息 不計免賠險包含在車損險裏了嗎 來了解一下詳細規則
- 海通計算機|DeepSeek初探:從V3到R1,高性能+低價格打開全新AI發展範式,推動AI在辦公、教育、醫療廣泛應用
- 白宮官員:特朗普將撤銷布林肯和沙利文安全許可
- 818是什麽星座(2007818是什麽星座)
- researchers是什麽意思(researchers是什麽意思)
- 中泰聯合聲明:以零容忍的堅決態度 加強打擊人口販運、電詐等跨境犯罪
- 亞是什麽意思(亞是什麽意思網絡用語)
- 什麽是兩岸關係的政治基礎
- RTX 40係列顯卡頻繁出現崩潰黑屏問題 專業人士分析原因
- 首創1000平超級文具節,得力用文創打響年輕化戰役
- 5000億元巨頭,籌劃重組!
- 美媒感歎:又一個“DeepSeek時刻”將至
- 木耳不能和什麽一起吃(多吃木耳有什麽好處和壞處)
- 62開頭的銀聯卡是什麽卡(62開頭的銀聯卡是什麽卡有什麽好處)
- 琅琊是現在的什麽地方(琅琊陽都是現在的什麽地方)
- 正部級李微微,被逮捕!
- 連“股神”都不炒了,巴菲特持有的美妝股大跌,背後原因何在?
站长推荐

石夕是什麽字(石夕組成是什麽字)

過往非農,皆是序章,“特馬”改革,最大擾動

中密控股:國際業務目前沒有受到關稅影響

波音因NASA登月計劃延期成本飆升 大裁400人以縮減開支

腺體腸化是什麽意思(灶性腺體腸化什麽意思)

goodfriend什麽意思(goodfriend什麽意思英文)

120是什麽星座(1201是什麽星座)

10萬以下的車買什麽好(十五萬元左右的車什麽車最好)

心情舒暢是什麽意思(心情莫名的舒暢是什麽意思)

什麽什麽相處(與什麽相處的日子)

新陳代謝什麽意思(人體新陳代謝是指什麽)

下周鋼價怎麽走,哪個品種還有機會?

321是什麽星座(321是什麽星座)

情投意合代表什麽生肖(情投意合指什麽生肖)

石破茂與特朗普會麵,美日“小集團”謀劃“大算盤”

10月4日是什麽星座(陽曆10月4日是什麽星座)

矽電股份1.6億資金補流存疑?資產負債率不高 業績暴漲背後大客戶關聯方突擊入股

建設銀行太原分行因占壓財政存款或者資金被罰5萬元

巴寶莉和博柏利有什麽區別(巴寶莉和博柏利是同一個牌子嗎)

多家券商部署DeepSeek形式曝光 未來將拓展至量化交易算法優化等領域
俄羅斯電信:波羅的海海底電纜遭破壞

新西蘭調整“黃金簽證”以吸引富裕移民

原貴州省地方金融監督管理局一級巡視員宋銳被開除黨籍

歐盟或削減美國進口汽車關稅求放過?歐洲議會官員稱“反脅迫工具”也在準備中

寶駿汽車靈語智艙與DeepSeek完成深度融合

腦內散在缺血灶是什麽意思(腦內小缺血灶嚴重嗎)

什麽然大什麽(什麽然大什麽什麽成語)

won什麽意思(i won什麽意思)

俄方回應特朗普稱曾與普京通話:“既不能確認、也不能否認”

棄權是什麽意思(被保險人棄權是什麽意思)
友情链接
- 楼继伟:地方政府可以出售资产还债|楼继伟|地方债
- 海关总署修订海南离岛免税政策 购物限制提至8000元|离岛免税|海南岛
- 央行开展200亿正回购 市场预计将延续偏松态势|央行|回购|利率
- 1月进出口总值同比下降10.8% 贸易顺差扩大87.5%|进出口|贸易顺差|一带一路
- 国资划转社保基金总体方案待明确|养老金|国资改革
- 五大首席经济学家解读CPI里的N个秘密|CPI
- 国务院部署重点督查 确保重大政策措施落地生根|国务院|督查
- 央行下调金融机构人民币存贷款基准利率|存款|贷款|利率
- 汇丰PMI初值跌至收缩区间 业内呼吁放松政策稳经济|PMI|指数|货币政策
- 精简审批投资项目网上并联核准制获批|国内财经|改革|投资
- 尹蔚民:今年城镇新成长劳动力1500万 就业压力巨大|尹蔚民|就业|城镇
- 官方:二季度经济增速将跌破7% 稳增长需加码|GDP增速
- 野村:明年亚洲多国将降息 中国1次降息4次降准|房地产|存款|利率
- 10月份中国CPI涨幅再创近五年来新低|CPI|价格上涨
- 中国交通2050概念初现 一带一路走廊入选三大战略|京津冀|交通运输
- 民生点评一带一路:国家资产负债表重构正式登台|一带一路|民生证券
- 国务院为企业减负再出实招 清除涉企任性收费|国务院|铁矿石|小微企业
- 外管局:一季度国际储备资产减少4925亿元|美元|国际|资产
- 统计局公布GDP初步核算情况:3季度同比增长7.3%|GDP|服务业|经济
- 神华等大煤企难撑煤价 市场低迷贸易商降价出售|大智慧|煤炭行业|能源
- 国办:建立投资协同监管机制 推动信息化和现代化|监管|投资|改革
- 国资划转社保基金总体方案待明确|养老金|国资改革
- 4月CPI料低于2% 为政策宽松留下空间|货币政策|CPI|物价
- 李克强达沃斯极目远眺 以滑雪畅论中国经济|李克强|达沃斯|中国经济
- 代表委员建议个税改革应引入家庭申报制度|个税改革
- 货币政策仍有继续微调的空间 降准概率大|货币政策|利率|通货膨胀
- 深化投融资体制改革:需创新投融资方式|投融资|投资主体
- 业内:央行不降准或因不愿加剧人民币汇率波动等因素|央行|降准|原因
- 一个真正的黄金时代|改革|国内财经|金麒麟
- 国务院:出口退税今年起由中央财政负担|出口退税|改革|退税
- 中信证券首席经济学家:预计2015年降准降息|中信证券|首席经济学家|降准降息
- 人社部部长:全民参保全国统筹 渐进延迟退休|尹蔚民|延迟退休
- 马骏分析油价下跌影响:CPI前低后高 贸易顺差扩大|马骏|油价
- 水十条启幕万亿投资盛宴 PPP解渴治污融资难题|九鼎投资|纳川股份|投资
- 前9月消费价格基本稳定 网络购物同比增长32.2%|网购|消费
- 发改委:不少PPP项目不具备实施条件|公用事业|PPP|发改委
- 全国房地产用地去年降25.5% 基础设施用地大增|房地产|基础设施
- 外汇局:中国有资本外流 但不是问题|外汇管理局|资本外流|人民币汇率
- 消费率近十年来有望首超50% 仍居三驾马车之冠|消费率|三驾马车|智慧生活
- 机构预计2015经济增速降至7% 地方债问题凸显|债券市场|经济|地方债
- 央行降息 人民币正式加入货币战|央行|降息|货币战
- 外管局:一季度国际储备资产减少4925亿元|美元|国际|资产
- 前4月规模以上工业企业利润降幅收窄|利润|工业企业
- 商务部:2015年信息消费规模将增两成|商务部|信息消费
- 央行公开市场周四无操作 本周投放300亿|央行|公开市场|300亿
- 外媒:央行人士称存款准备金会逐渐下降|降准|存款保险
- 社科院研究所:实体经济低迷 金融风险持续累积|实体经济|低迷
- 中金:内需总体仍在低位 政策放松空间大|中金|宏观|顺差
- 陈经纬:建设一带一路应发挥港澳台和海外华侨华人的作用|香港|海上丝绸之路|一带一路
- 我国贸易顺差再创新高 全年进出口增速不及预期|贸易顺差|外贸|进出口